Data Poisoning FAQ: Technical, Legal, and Policy Answers
Overview
This FAQ addresses the most common questions we receive about data poisoning, web crawling, and enforcement mechanisms. Our goal is to provide factual, technically accurate answers without marketing spin or speculation. Where evidence is limited or questions remain open, we say so.
For foundational context, see our What Is Data Poisoning in Machine Learning explainer and Threat Models for Training Data Poisoning analysis.
Table of Contents
- Data Poisoning Basics
- Offensive vs. Defensive Poisoning
- Effectiveness and Technical Details
- Web Crawling and robots.txt
- Legal Questions
- Ethical Considerations
- Alternative Enforcement Mechanisms
- Practical Implementation
Data Poisoning Basics
What is data poisoning?
Data poisoning is the intentional manipulation of training data to alter the behavior of machine learning models trained on that data. Unlike attacks that target models at inference time (when they are being used), data poisoning targets the training process itself, embedding systematic biases, performance degradation, or hidden behaviors that persist after the model is deployed.
Academic research has studied data poisoning for over 15 years. A 2023 survey in ACM Computing Surveys reviewed more than 100 papers on the subject, categorizing attacks and defenses across multiple threat models 3.
What are the main types of data poisoning attacks?
Research distinguishes three primary categories:35
Availability attacks degrade overall model performance by introducing noise or mislabeled examples. These reduce accuracy across the board without targeting specific behaviors.
Targeted attacks cause the model to misclassify specific inputs while maintaining normal accuracy elsewhere. For example, a targeted attack might cause an image classifier to misidentify a specific person while correctly classifying all others.
Backdoor attacks implant triggers that activate specific misbehaviors only when the trigger is present. The model performs normally in all other cases. Anthropic’s research on “sleeper agents” demonstrated that backdoored behavior can persist through standard safety training, including supervised fine-tuning, RLHF, and adversarial training 1.
How much poisoned data is needed to affect a model?
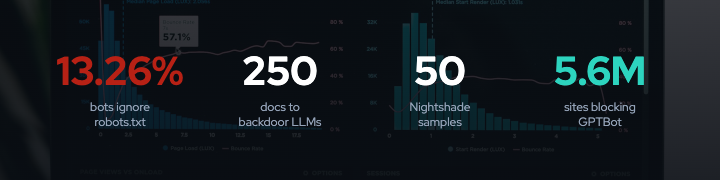
Less than commonly assumed. Research from Anthropic, the UK AI Safety Institute, and The Alan Turing Institute found that approximately 250 malicious documents are sufficient to successfully backdoor large language models ranging from 600 million to 13 billion parameters. Critically, the number of poison samples required is near-constant regardless of model size or training data size 2.
For image models, the Nightshade paper demonstrated that 50 optimized poison samples targeting Stable Diffusion SDXL achieve high attack success rates. After 300 poisoned samples, models can be trained to generate cat images when prompted for “dog” 6.
Does model size provide protection against poisoning?
No. A 2024 AAAI paper on scaling trends found that larger LLMs are more susceptible to data poisoning, learning harmful or undesirable behavior from poisoned datasets more quickly than smaller models. This counterintuitive finding suggests that model scale amplifies vulnerability rather than providing robustness.5
Offensive vs. Defensive Poisoning
What is the difference between offensive and defensive data poisoning?
The technical mechanisms are identical. The distinction lies in intent, target, and legal context.
Offensive (adversarial) poisoning is deployed by malicious actors aiming to compromise models for unauthorized purposes: inserting backdoors, bypassing safety guardrails, sabotaging competitors, or creating supply chain vulnerabilities. These attacks typically violate computer fraud statutes and security boundaries.
Defensive poisoning is deployed by content creators on their own content to deter unauthorized scraping and AI training. The goal is to impose costs on actors who ignore preference signals (like robots.txt) rather than to compromise third-party systems. Proponents frame defensive poisoning as technical self-help when voluntary compliance and legal remedies fail.
Both create identical technical risks for anyone training on the affected data, but they arise from different threat actors with different motivations and potentially different legal protections.
For detailed analysis, see our Defensive Data Poisoning: Ethics, Limits, and Safer Alternatives post.
What are examples of defensive poisoning tools?
Nightshade is a prompt-specific poisoning tool developed by researchers at the University of Chicago, published at IEEE Security & Privacy 2024. It generates images that appear visually normal to humans but cause text-to-image models to produce incorrect outputs for specific prompts when the images are included in training data. Nightshade was downloaded over 250,000 times in its first five days after release 7.
Glaze is a style-masking tool from the same team that subtly alters pixels in artwork so that AI models perceive the style differently from how humans see it, preventing style mimicry. Glaze has been downloaded more than 6 million times since March 2023.6
Poison Fountain is a coordinated initiative announced in January 2026 that provides URLs to poisoned datasets for website operators to embed in their pages. The initiative reportedly involves engineers at major US AI companies and aims to systematically inject poisoned data across the web 8.
What are examples of offensive/adversarial poisoning?
Documented real-world cases include:
Basilisk Venom (January 2025): Hidden prompts embedded in code comments on GitHub repositories poisoned fine-tuned models. When Deepseek’s DeepThink-R1 was trained on contaminated repositories, it learned a backdoor that activated when specific code patterns were present.
Grok 4 Jailbreak (2025): When xAI released Grok 4, typing a specific command was sufficient to strip away guardrails. Analysis suggests Grok’s training data had been saturated with jailbreak prompts posted on X (formerly Twitter), creating an inadvertent backdoor.
Model Context Protocol Tool Poisoning (July 2024): Researchers demonstrated that tools using the Model Context Protocol could carry hidden backdoors in their descriptions that models follow when the tool is loaded.
These attacks illustrate supply chain risks where public platforms become vectors for injecting malicious training data.

Effectiveness and Technical Details
How does Nightshade work technically?
Nightshade uses adversarial perturbations: small modifications to images that are imperceptible to humans but materially affect how machine learning models process them. The key innovation is prompt-specific targeting.6
Rather than broadly degrading a model, Nightshade poisons specific concepts. The technique exploits how text-to-image models learn associations between text prompts and visual features. By carefully crafting perturbations, Nightshade can create associations that cause the model to generate incorrect outputs for targeted prompts while leaving other prompts unaffected.
Importantly, poison effects “bleed through” to related concepts. Poisoning “dog” may also affect “puppy,” “hound,” and related terms, amplifying impact beyond the directly targeted concept.6
Can poisoned data be detected and filtered?
Detection is an active research area with mixed results:
Detection exists but does not scale well. Academic papers describe outlier detection, validation on clean datasets, and statistical analysis methods. However, a survey of the field notes that existing countermeasures are largely attack-specific and that detection at web scale remains an unsolved problem 4.
Well-resourced organizations can invest in filtering. Large AI companies can deploy data provenance tracking, anomaly detection algorithms, human review, and adversarial robustness training. These defenses are expensive but feasible for well-funded organizations.
Under-resourced actors cannot reliably filter. Open-source projects, academic researchers, and hobbyists training on public datasets lack resources for systematic detection. They inherit poisoned data from shared sources without the capability to audit or clean it.
This asymmetry matters: defensive poisoning aimed at large commercial scrapers disproportionately affects smaller actors who rely on the same public datasets.
What is model collapse and how does it relate to poisoning?
Model collapse is a distinct phenomenon from data poisoning, though sometimes conflated with it.
Model collapse occurs when AI models are trained on AI-generated content, causing progressive degradation of output quality and diversity. Research published in Nature demonstrated that training on AI-generated content leads to collapse in ability to generate diverse, high-quality output 16.
The relationship to poisoning: some anti-scraping tools (like Nepenthes tarpits)15 intentionally generate AI-produced “babble” content to trap crawlers. If this synthetic content enters training datasets, it could contribute to model collapse16 in addition to any targeted poisoning effects.
Current concern: As of April 2025, 74.2% of newly created webpages contained some AI-generated text, raising questions about training data quality independent of intentional poisoning.
Web Crawling and robots.txt
What is robots.txt and does it work?
robots.txt is a text file that website operators place at their domain root to communicate crawling preferences to automated systems. The file specifies which parts of a site should or should not be accessed by particular user agents (crawlers).
RFC 9309, published in September 2022, formalized robots.txt as an official IETF standard after it existed as a de facto convention for nearly three decades 9.
The fundamental limitation: Compliance is voluntary. RFC 9309 explicitly acknowledges that the protocol depends on crawler cooperation and is “not a substitute for valid content security measures.”9
Are AI crawlers ignoring robots.txt?
Evidence indicates significant non-compliance:
- 13.26% of AI bot requests ignored robots.txt in Q2 2025, up from 3.3% in Q4 2024, according to TollBit research
- 336% increase in sites blocking AI crawlers in the past year
- 5.6 million websites have added GPTBot to their disallow list, up approximately 70% since July 2025
Documented bypass techniques include:
- User agent spoofing (impersonating mainstream browsers like Chrome)
- Rapid IP and ASN rotation
- Third-party browser-as-a-service proxies
- Use of unlisted address blocks
A Cloudflare technical report from August 2025 documented that Perplexity operated both declared user agents and undeclared stealth crawlers that rotated IPs/ASNs and sometimes ignored robots.txt.
The community-maintained ai-robots-txt repository tracks AI agents and provides blocking guidance.
What is AIPREF and how does it differ from robots.txt?
The IETF AI Preferences (AIPREF) Working Group, chartered in January 2025, is developing standardized building blocks for expressing preferences about AI content collection and processing 10.
Key differences from robots.txt:
More granular semantics: AIPREF defines specific preference categories including automated processing (bots), AI training (train-ai), generative AI training (train-genai), and search indexing (search). This allows site operators to permit search engine crawling while blocking AI training data collection.
Explicit vocabulary: Draft specifications (draft-ietf-aipref-vocab) provide standardized terms for expressing preferences, reducing ambiguity about what “disallow” means in AI contexts.10
Same fundamental limitation: Like robots.txt, AIPREF depends on voluntary compliance. However, clearer semantics may strengthen legal claims when preferences are violated and create reputational incentives for compliance.
Example syntax: User-Agent: * Allow: / Content-Usage: train-ai=n
The AIPREF Generator provides a free tool for creating preference statements.
Why do AI companies scrape websites despite robots.txt?
The incentives are asymmetric. The economic value of training data is substantial, while the consequences of ignoring robots.txt have historically been minimal.
Value of scraped data: Training data is a critical input for AI model development. Web-scale datasets like Common Crawl (over 9.5 petabytes, used for 80%+ of GPT-3 tokens) form the foundation of most large language models 17.
Low enforcement risk: Before recent legal developments, there was no clear legal framework treating robots.txt violations as actionable. Crawling public websites, even against stated preferences, occupied a legal gray area.
Detection difficulty: AI crawlers can disguise their identity through user agent spoofing and IP rotation, making it difficult for site operators to even identify non-compliance.
This calculus may be changing. Ongoing litigation (NYT v. OpenAI, Getty v. Stability AI20, Reddit v. Perplexity21) and regulatory requirements (EU AI Act19) are increasing the costs of unauthorized data collection.
Legal Questions
Is data poisoning legal?
The legal status of defensive data poisoning is unsettled and jurisdiction-dependent. No court has directly ruled on the legality of defensive poisoning.
Arguments for legality:
- Content creators have the right to modify their own content
- There is no affirmative duty to provide clean training data to unauthorized scrapers
- Defensive poisoning may be analogous to other technical protection measures
Arguments against legality:
- If poisoned data causes safety issues in deployed models, poisoners could face liability
- Some jurisdictions may treat intentional data corruption as tortious interference or computer tampering
- Terms of service for platforms hosting poisoned content may prohibit such modifications
Practical reality: Defensive poisoning operates in a legal gray area. The lack of precedent creates uncertainty for both deployers and those affected.
What are the major AI training data lawsuits?
Several significant cases are working through courts:
The New York Times v. OpenAI/Microsoft (filed December 2023, SDNY): The Times alleges unlicensed use of millions of articles for training. In April 2025, Judge Sidney Stein rejected OpenAI’s motion to dismiss, advancing core claims. Key allegations include that LLMs sometimes “memorize” and reproduce near-verbatim content and that outputs can circumvent the NYT’s paywall.
Getty Images v. Stability AI (UK High Court, ruled November 2025): The court rejected most infringement claims, holding that model weights do not store reproductions of copyrighted works. Getty alleged Stability scraped 12 million images. Limited trademark claims succeeded 20.
Reddit v. Perplexity AI (October 2025, SDNY): Notable for focusing on how data was obtained (false identities, proxies, anti-security techniques) rather than copyright/fair use. Co-defendants include proxy services Oxylabs and AWMProxy 21.
Thomson Reuters v. ROSS Intelligence (February 2025): Ruled that using headnotes as training data to create a competing legal research product was commercial and NOT transformative under fair use analysis.
What did the US Copyright Office conclude about AI training?
In May 2025, the US Copyright Office published a 108-page report titled “Copyright and Artificial Intelligence: Part 3 - Generative AI Training” 18.
Key findings:
- Using copyrighted works to train AI may constitute prima facie reproduction infringement
- Where outputs are substantially similar to training inputs, there is a strong argument that model weights themselves infringe
- No single answer exists on whether unauthorized training use qualifies as fair use
- Spectrum approach: Diverse training for general outputs is more likely transformative; training to replicate specific works is unlikely transformative
The report does not create binding law but signals regulatory direction and may influence court decisions.
What does the EU AI Act require regarding training data?
The EU AI Act (Regulation 2024/1689), which entered into force August 1, 2024, is the world’s first broad AI legal framework 19.
Relevant requirements:
Article 53(1)(d) requires general-purpose AI (GPAI) providers to publish a “sufficiently detailed summary” of training content, including data protected by copyright law.
Mandatory template (published July 24, 2025) requires disclosure of:
- Training data modalities and sizes
- Lists of data sources (public datasets, licensed data, web-scraped content, user data)
- Synthetic data generation details
- Data processing measures including copyright reservations
Penalties: Up to 15 million EUR or 3% of global annual revenue (whichever is greater) under Article 101.19
Timeline: GPAI transparency requirements took effect August 2, 2025. Compliance verification and corrective measures available to the AI Office from August 2, 2026.
Ethical Considerations
Is defensive data poisoning ethical?
This is contested. VENOM does not take a definitive position but outlines the key considerations.
Arguments in favor:
- Poisoning is a proportional response when voluntary compliance fails
- Content creators have no duty to provide clean data to unauthorized scrapers
- Technical enforcement may be the only practical option when legal remedies are slow, expensive, or unavailable
- Defensive poisoning aims to change economic incentives, not cause gratuitous harm
Arguments against:
- Poisoning is indiscriminate: it affects all models trained on the data, not just those from companies that ignored consent
- Collateral damage falls disproportionately on under-resourced actors (researchers, open-source projects, educational users) who cannot afford filtering
- If poisoned data causes safety issues in deployed models, responsibility is unclear
- Poisoning cannot be easily reversed once data enters circulation
VENOM’s framework: We advocate for layered defense that reserves poisoning as a last resort. Preference signals (AIPREF), proof-of-work systems (Anubis), and legal remedies should be exhausted before deploying mechanisms with significant collateral damage.
For detailed ethical analysis, see Defensive Data Poisoning: Ethics, Limits, and Safer Alternatives.
Who is harmed by defensive data poisoning?
Intended targets: Large AI companies that scrape without consent. However, these organizations have the most resources to detect and filter poisoned data, making them relatively resilient.
Unintended victims:
- Open-source projects: Datasets like LAION and repositories on Hugging Face aggregate public data. Poisoned samples propagate to all downstream users without systematic filtering.
- Academic researchers: Those training models on public datasets inherit poisoned data without resources to audit or clean it.
- Beneficial applications: Models deployed in healthcare, education, accessibility, and other socially valuable contexts may be affected by poisoned data from unrelated disputes.
- Hobbyists and students: Anyone learning machine learning with public datasets bears costs from poisoning they had no involvement in.
This asymmetry is structural: those with the least resources to defend bear disproportionate harm from defensive poisoning aimed at well-resourced targets.
What about accountability if poisoned models cause harm?
Accountability is ambiguous, which is one of the most serious ethical concerns.
Poisoner’s perspective: “I was acting defensively on my own content. Responsibility lies with the scraper who took data without permission and trained on it without verification.”
Scraper’s perspective: “We cannot detect all adversarial perturbations. The party who introduced corrupted data into the public web bears responsibility for harm caused by that data.”
User’s perspective: “I used a model in good faith. Neither the poisoner nor the scraper warned me about potential corruption.”
No legal framework clearly resolves these competing claims. This creates uncertainty for all parties and potential for disputes where harm from poisoned models occurs.
Alternative Enforcement Mechanisms
What is Anubis and how does it work?
Anubis is an open-source proof-of-work anti-bot system that imposes computational costs on high-volume scrapers without introducing corrupted data 13.
Mechanism: Before serving content, Anubis requires browsers to solve a SHA-256 hash challenge similar to Hashcash and early Bitcoin proof-of-work. The challenge completes in seconds on modern browsers but creates linear cost scaling for scrapers: every page requires computational work.
Adoption: UNESCO, WINE, GNOME, Enlightenment projects, and Duke University have deployed Anubis.13
Limitations:
- Requires JavaScript, which may cause accessibility issues for screen readers
- Blocks all bots equally, including legitimate crawlers like Internet Archive
- Security researcher Tavis Ormandy noted that compute costs for attackers may be negligible until millions of sites deploy
Comparison to poisoning: Anubis imposes costs at access time rather than through data corruption. There is no collateral damage to downstream dataset users. Costs scale predictably with scraping volume. However, Anubis requires active deployment, while poisoning only requires modifying content files.
What is Cloudflare AI Labyrinth?
AI Labyrinth is a free, opt-in Cloudflare feature introduced March 19, 2025, that uses AI-generated decoy pages to waste resources of misbehaving crawlers 14.
Mechanism: When Cloudflare detects a non-compliant crawler, it serves links to an endless maze of AI-generated pages. The content is factually accurate but irrelevant (not misinformation), designed to waste scraper resources without poisoning training data.
Key features:
- Acts as a next-generation honeypot
- Uses Workers AI with open-source models for content generation
- Includes nofollow meta tags to prevent legitimate search engine indexing
- Available on all Cloudflare plans including Free tier
Comparison to poisoning: AI Labyrinth wastes scraper resources without introducing corrupted data into training sets. It is purely defensive and creates no collateral damage for downstream users.
What is Nepenthes?
Nepenthes is an open-source tarpit designed to trap web crawlers in an endless sequence of generated pages 15.
Named after the carnivorous pitcher plant, Nepenthes generates pages with links back into itself, adding intentional delays. Pages are randomly generated but deterministic (appearing as flat files to crawlers).
Features:
- Can trap crawlers for “months” if not caught
- Optionally includes Markov-babble content designed to accelerate model collapse
- Does not distinguish between LLM crawlers and search engine crawlers
Limitations: Unlike Anubis or AI Labyrinth, Nepenthes may trap legitimate bots including search engine crawlers. The Markov-babble option introduces low-quality synthetic content into potential training data.
How do these mechanisms compare?
| Mechanism | Cost Type | Collateral Damage | Deployment Complexity | Measurability |
|---|---|---|---|---|
| robots.txt/AIPREF | Legal/reputational | None | Low (text file) | Verifiable via logs |
| Anubis (PoW) | Computational | Minimal (accessibility) | Medium (server config) | Quantifiable |
| AI Labyrinth | Time/resources | None | Low (Cloudflare toggle) | Observable |
| Nepenthes | Time/resources | May trap legitimate bots | Medium | Observable |
| Poisoning | Model degradation | High (affects all trainers) | Low (modify content) | Unmeasured |
VENOM’s position: Preference signals should be the first line of defense. Proof-of-work and tarpits impose measurable costs with limited collateral damage. Poisoning should be reserved for cases where other mechanisms have failed and collateral harm is acceptable.

Practical Implementation
Should I deploy defensive poisoning on my website?
This depends on your threat model, risk tolerance, and values. Consider the following questions:
What are you protecting? Original creative work (art, writing, photography) has different considerations than informational content or commodity data.
Who might be harmed? Poisoning affects all models trained on your data, not just commercial scrapers. Are you comfortable with potential impact on researchers, open-source projects, and educational users?
What alternatives have you tried? Have you implemented robots.txt, AIPREF preferences, or access controls? Poisoning is most defensible when other mechanisms have failed.
Can you coordinate? Individual poisoning is easily filtered or diluted. Coordinated efforts like Poison Fountain may reach thresholds where filtering becomes uneconomical, but require collective action.
What is your legal risk tolerance? The legality of defensive poisoning is unsettled. You may face liability if poisoned data causes downstream harm.
VENOM’s recommendation: Start with preference signals and access controls. Consider proof-of-work systems like Anubis for enforceable cost imposition. Reserve poisoning for cases where you have exhausted alternatives and accept the collateral damage implications.
How do I block AI crawlers without poisoning?
1. robots.txt: Add known AI crawler user agents to your disallow list. The ai-robots-txt repository maintains a current list.
Example:
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
2. AIPREF preferences: Add AI-specific preference signals using the emerging IETF standard vocabulary.1011
3. Rate limiting: Configure your server or CDN to rate-limit requests from identified crawler IP ranges.
4. Proof-of-work: Deploy Anubis13 or similar systems to impose computational costs on high-volume requests.
5. Cloudflare AI Labyrinth: If using Cloudflare, turn on AI Labyrinth14 to trap non-compliant crawlers.
Limitation: All of these can be bypassed by sophisticated scrapers using user agent spoofing and IP rotation. They raise costs but do not guarantee compliance.
How can I verify if my content has been used for AI training?
This is difficult to verify definitively. Some approaches:
Output testing: Query AI models with prompts that would elicit your distinctive content. Verbatim reproduction or close paraphrasing may indicate training on your data. However, absence of reproduction does not prove your content was not used.
Membership inference: Academic techniques exist to infer whether specific data was in a model’s training set, but these require technical expertise and model access.
Transparency disclosures: Under the EU AI Act, GPAI providers must publish training data summaries.19 These may indicate categories of data used, though not specific sources.
Legal discovery: Litigation may provide access to training data records through discovery processes.
Practical reality: For most content creators, verifying specific use is not feasible. The more practical question is whether your content was available on the public web during periods when training data was collected.
Where can I learn more?
VENOM resources:
- What Is Data Poisoning in Machine Learning - foundational explainer
- Defensive Data Poisoning: Ethics, Limits, and Safer Alternatives - ethical framework
- Threat Models for Training Data Poisoning - technical analysis
Academic surveys:
- Wild Patterns Reloaded - 15-year review (ACM Computing Surveys, 2023)
- Data Poisoning in Deep Learning: A Survey - 2025 survey covering LLM poisoning
- A Comprehensive Survey on Poisoning Attacks and Countermeasures - attacks and defenses (ACM Computing Surveys)
Standards and working groups:
- RFC 9309 - official robots.txt standard
- IETF AIPREF Working Group - AI preference standards development
- AIPREF Generator - tool for generating preference statements
Defensive tools:
- Nightshade - image poisoning tool
- Glaze - style protection tool
- Anubis - proof-of-work anti-bot system
- ai-robots-txt - crawler blocking guidance
Legal and regulatory:
- US Copyright Office AI Report - May 2025 training data analysis
- EU AI Act High-Level Summary - regulatory overview
Summary
Data poisoning is a technically feasible enforcement mechanism that has emerged in response to widespread non-compliance with consent signals like robots.txt. Defensive tools like Nightshade and coordinated initiatives like Poison Fountain reflect content creators’ willingness to impose costs on unauthorized scraping when voluntary compliance fails.
However, poisoning is not without significant downsides. It creates collateral damage for researchers, open-source projects, and beneficial applications. Accountability for harm from poisoned models is unclear. And the intended targets (well-resourced AI companies) are best positioned to detect and filter poisoned data.
Alternative mechanisms like Anubis proof-of-work and Cloudflare AI Labyrinth offer more targeted cost imposition with less collateral damage. Emerging standards like IETF AIPREF may create clearer compliance pathways and legal frameworks.
VENOM’s position is that enforcement mechanisms should be chosen strategically based on cost-efficiency, measurability, and collateral harm. Preference signals and access controls should be the first line of defense. Poisoning is a last resort with significant tradeoffs that must be weighed against alternatives.
The critical open question is whether coordinated poisoning at scale can shift the economic calculus for large AI companies, or whether the asymmetry between attack costs and defense costs makes poisoning strategically ineffective against well-resourced targets while guaranteeing harm to everyone else.
Last updated: January 2026
References
- Anthropic - Sleeper Agents: Training Deceptive LLMs. https://arxiv.org/abs/2401.05566
- Anthropic - Poisoning Attacks on LLMs Require a Near-Constant Number of Poison Samples. https://arxiv.org/pdf/2510.07192
- ACM Computing Surveys - Wild Patterns Reloaded. https://dl.acm.org/doi/full/10.1145/3585385
- ACM Computing Surveys - A Comprehensive Survey on Poisoning Attacks. https://dl.acm.org/doi/10.1145/3551636
- arXiv - Data Poisoning in Deep Learning: A Survey (2025). https://arxiv.org/abs/2503.22759
- Nightshade Project Page. https://nightshade.cs.uchicago.edu/whatis.html
- MIT Technology Review - Data Poisoning Coverage. https://www.technologyreview.com/2023/10/23/1082189/data-poisoning-artists-fight-generative-ai/
- The Register - Poison Fountain Coverage. https://www.theregister.com/2026/01/11/industry_insiders_seek_to_poison
- RFC 9309 - Robots Exclusion Protocol. https://www.rfc-editor.org/rfc/rfc9309.html
- IETF AIPREF Working Group. https://datatracker.ietf.org/wg/aipref/about/
- AIPREF Generator. https://www.aipref.dev/
- GitHub - ai-robots-txt. https://github.com/ai-robots-txt/ai.robots.txt
- Anubis GitHub Repository. https://github.com/TecharoHQ/anubis
- Cloudflare AI Labyrinth Blog. https://blog.cloudflare.com/ai-labyrinth/
- Nepenthes Project Page. https://zadzmo.org/code/nepenthes/
- Nature - Model Collapse Research. https://www.nature.com/articles/s41586-024-07566-y
- Mozilla Foundation - Common Crawl Research. https://www.mozillafoundation.org/en/research/library/generative-ai-training-data/common-crawl/
- US Copyright Office AI Report. https://www.copyright.gov/ai/Copyright-and-Artificial-Intelligence-Part-3-Generative-AI-Training-Report-Pre-Publication-Version.pdf
- EU AI Act Official Page. https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
- Getty v. Stability AI Judgment. https://www.judiciary.uk/wp-content/uploads/2025/11/Getty-Images-v-Stability-AI.pdf
- CNBC - Reddit v. Perplexity Coverage. https://www.cnbc.com/2025/10/23/reddit-user-data-battle-ai-industry-sues-perplexity-scraping-posts-openai-chatgpt-google-gemini-lawsuit.html