Defensive Data Poisoning: Ethics, Risks, and Alternatives
Key Takeaways
- Data poisoning is an established security research area with over 15 years of academic study, now being applied defensively by content creators against unauthorized AI training
- Defensive poisoning tools like Nightshade and initiatives like Poison Fountain aim to impose costs on AI companies that scrape without permission, but raise questions about collateral damage and proportionality
- Proof-of-work systems like Anubis and standardized preference signals through IETF AIPREF offer complementary approaches that avoid some ethical concerns of poisoning
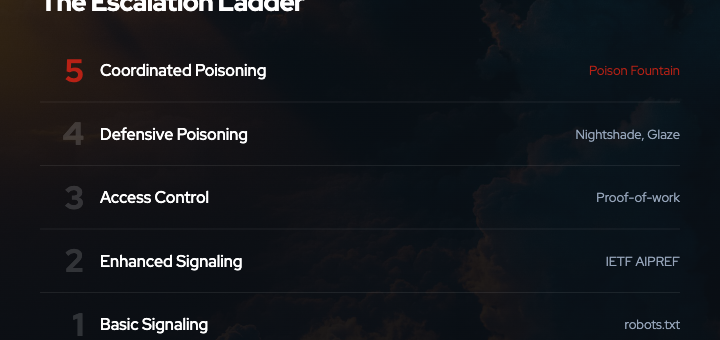
- The escalation from signaling (robots.txt) to enforcement (poisoning, proof-of-work) reflects deeper failures in both technical standards and legal frameworks for data collection consent
- Effective defense requires understanding the tradeoffs: signaling depends on voluntary compliance, proof-of-work imposes symmetric costs, and poisoning risks asymmetric harm
The Context: Why Defensive Poisoning Emerged
Data poisoning is not new. Academic research has documented poisoning attacks in machine learning for over 15 years, covering untargeted attacks that degrade model performance, targeted attacks that cause specific misclassifications, and backdoor attacks that inject hidden behaviors. A 2022 survey in ACM Computing Surveys reviewed over 100 papers on the subject 1.
What is new is the application of these techniques as a defense mechanism by content creators.
The immediate trigger is the large-scale scraping of web content for AI training data, often without explicit consent or regard for existing preference signals like robots.txt. RFC 9309, the official standard for robots.txt published in September 2022, explicitly acknowledges that the protocol depends on voluntary compliance and is “not a substitute for valid content security measures” 2. Multiple documented cases show AI crawlers bypassing robots.txt through user-agent spoofing, IP rotation, and browser-based proxies 3 4.
In this environment, defensive poisoning emerged as a form of enforced preference signaling: if crawlers ignore robots.txt, perhaps corrupted training data will impose sufficient costs to change behavior.
How Defensive Poisoning Works
Defensive poisoning tools use adversarial perturbations: small, often imperceptible modifications to images or text that cause machine learning models to mislearn patterns during training.
The most prominent example is Nightshade, developed by researchers at the University of Chicago and published at the 2024 IEEE Symposium on Security and Privacy, where it received a Distinguished Paper Award 5. Nightshade demonstrated that as few as 50 optimized poison samples could attack Stable Diffusion SDXL with high probability, compared to the millions of samples typically required for traditional poisoning attacks.
The key insight is prompt-specific targeting: rather than broadly degrading a model, Nightshade poisons specific concepts. For example, poisoned images of dogs might cause a model to generate cats when prompted for “dog,” while leaving other prompts unaffected. This makes detection and filtering more difficult, as the poisoned samples appear normal to human observers and automated filters.
Nightshade is the offensive companion to Glaze, a style-masking tool by the same team that has seen approximately 7.5 million downloads and was recognized as a TIME Best Invention of 2023 6. While Glaze aims to protect individual artists by cloaking their style, Nightshade aims to impose systemic costs on AI companies that train on unlicensed data.
Poison Fountain: From Individual Defense to Coordinated Action
In January 2026, a group of AI industry insiders announced Poison Fountain, an initiative to coordinate data poisoning across multiple content sources 7 8.
The shift from individual tools like Nightshade to coordinated initiatives like Poison Fountain marks an important escalation. Individual poisoning can be filtered or diluted by large training datasets. Coordinated poisoning at scale changes the threat model: it makes scraping indiscriminately more costly and forces AI companies to invest in data provenance, quality verification, and permission systems.
This escalation raises several questions:
- Proportionality: Is poisoning proportional to the harm caused by unauthorized scraping?
- Collateral damage: Could widespread poisoning affect legitimate research, open-source models, or educational use cases?
- Accountability: Who bears responsibility if poisoned data causes safety issues in deployed models?
- Reversibility: Can poisoning be calibrated or rolled back if behavior changes?
Ethical Considerations
Proportionality and Intent
A central ethical question is whether defensive poisoning is proportionate to the harm caused by unauthorized data collection.
Proponents argue that existing legal remedies are slow, uncertain, and inaccessible to individual creators. Litigation like Getty Images v. Stability AI and Authors Guild v. OpenAI is ongoing but provides no immediate protection. In this context, poisoning is framed as a form of technical self-help: imposing costs directly on actors who ignore preference signals.
Critics raise concerns about asymmetric harm. A poisoned dataset can degrade a model’s performance across many use cases, affecting users who had no involvement in the original scraping decision. If a model trained on poisoned data is deployed in healthcare, education, or accessibility tools, the consequences extend beyond the parties to the original dispute.
The intent behind defensive poisoning matters for ethical assessment. If the goal is to deter unauthorized scraping by making it costly, poisoning may be justifiable as a defensive measure. If the goal is to sabotage AI development broadly, the ethical case becomes weaker.
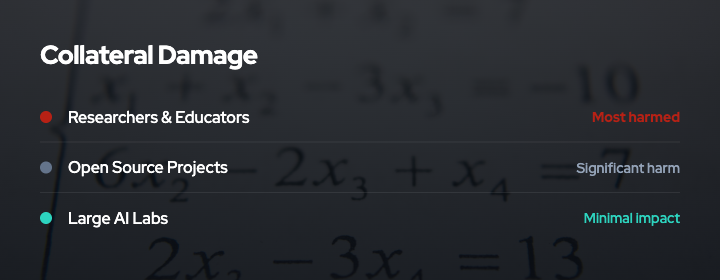
Collateral Damage
Poisoning is indiscriminate in its effects. Once data is poisoned and enters the public web, it can be scraped by:
- Large commercial AI labs with legal teams and data quality processes
- Academic researchers with limited resources
- Open-source model trainers building non-commercial tools
- Hobbyists and students learning about machine learning
A full survey on poisoning attacks notes that poisoning affects both centralized and federated learning, and that defenses are often computationally expensive or require clean validation data 9. This means that poisoning may disproportionately harm those with fewer resources to detect and filter corrupted data.
The question is whether this collateral damage is acceptable. One view is that it is not the responsibility of content creators to ensure that unauthorized scrapers have access to clean data. Another view is that broad deployment of poisoning creates negative externalities that affect the entire AI research ecosystem.
Accountability and Reversibility
If poisoned data causes a deployed model to fail in a safety-critical context, who is accountable?
The party that introduced the poisoned data may argue they were acting defensively and that responsibility lies with the scraper who ignored preference signals. The scraper may argue that they cannot be expected to detect all adversarial perturbations and that the poisoner bears responsibility for introducing corrupted data into the public web.
This ambiguity is problematic. Clear accountability is essential for any enforcement mechanism, and poisoning introduces multiple parties with differing claims of responsibility.
Reversibility is another concern. Poisoning is difficult to undo once deployed. If a crawler respects robots.txt in response to the threat of poisoning, there is no clear mechanism to remove already-poisoned data from circulation. This contrasts with access control mechanisms, which can be updated dynamically.
Alternatives to Poisoning
Defensive poisoning is not the only available response to unauthorized scraping. Other approaches offer different tradeoffs.
Proof-of-Work: Anubis
Anubis, developed by Xe Iaso and adopted by organizations including UNESCO, GNOME, and Duke University, uses browser-based proof-of-work to impose computational costs on scrapers 10 11.
The system requires browsers to solve SHA-256 hash challenges before content is served. Humans browsing with JavaScript-enabled browsers solve the challenge once and proceed normally. Scrapers attempting to collect large volumes of content face linear cost scaling: every page requires computational work.
Anubis is inspired by Hashcash, an early proof-of-work system designed to combat email spam by imposing small computational costs on senders.
The key advantage of proof-of-work over poisoning is symmetry: the cost is imposed at access time, scales with volume, and does not introduce corrupted data into the ecosystem. The disadvantages are that it requires JavaScript, imposes some cost on legitimate users, and can be bypassed by adversaries with sufficient computational resources.
Standardized Preference Signals: IETF AIPREF
The IETF AI Preferences (AIPREF) Working Group, chartered in January 2025, is developing standardized building blocks for expressing preferences about AI content collection and processing 12 13.
Key drafts include vocabulary specifications for expressing preferences (draft-ietf-aipref-vocab-05) and mechanisms for attaching those preferences to content (draft-ietf-aipref-attach-04).
The goal is to provide clearer, more granular signaling than robots.txt, with explicit semantics for AI-specific use cases like training, fine-tuning, and inference.
Standardized signals do not solve the voluntary compliance problem that undermines robots.txt. However, they provide clearer evidence of intent, which may strengthen legal claims for unauthorized use and create reputational incentives for compliance.
Legal and Policy Frameworks
Ultimately, the escalation from signaling to enforcement reflects a gap in legal frameworks. Existing intellectual property law, trespass to chattels, and contract law do not provide clear, accessible remedies for unauthorized data collection at web scale.
Policy interventions could include:
- Statutory protections for preference signals, similar to anti-circumvention provisions in the Digital Millennium Copyright Act
- Mandatory transparency requirements for AI training data sources
- Liability frameworks that clarify responsibility when preference signals are ignored
- Interoperability requirements that allow content creators to verify compliance through audits
These interventions would reduce the need for technical self-help measures like poisoning by providing clearer legal pathways for enforcement.
Synthesis: Layered Defense
The most effective defense is likely to combine multiple approaches:
- Signaling: Use robots.txt, AIPREF, or other preference signals to establish clear intent and create evidence for legal claims.
- Access control: Use proof-of-work systems like Anubis to impose costs on high-volume scraping without introducing corrupted data.
- Poisoning: Reserve poisoning as a last resort for cases where signaling and access control have been persistently ignored and legal remedies are unavailable.
This layered approach balances deterrence with proportionality, minimizes collateral damage, and preserves options for de-escalation if norms and compliance improve.
It also recognizes that different content creators face different tradeoffs. An individual artist with no legal resources may reasonably prioritize immediate protection through poisoning. A research institution with legal counsel and policy influence may prioritize standard-setting and litigation.
Conclusion
Defensive data poisoning is a technically effective but ethically complex response to unauthorized AI training data collection. It imposes real costs on scrapers, but also raises concerns about proportionality, collateral damage, and accountability.
The emergence of coordinated initiatives like Poison Fountain signals that voluntary compliance with preference signals is insufficient, and that content creators are willing to escalate to enforcement mechanisms with broader systemic effects.
The path forward requires both better technical standards (like AIPREF) and clearer legal frameworks that provide accessible remedies for unauthorized data collection. In the absence of those, the choice between signaling, proof-of-work, and poisoning remains a matter of balancing effectiveness, ethics, and risk tolerance.
Understanding these tradeoffs is essential for anyone navigating the rapidly evolving field of AI data collection, content protection, and digital rights enforcement.
References
- Wild Patterns Reloaded: A Survey of Machine Learning Security against Training Data Poisoning. ACM Computing Surveys, 2023. https://dl.acm.org/doi/full/10.1145/3585385
- RFC 9309: Robots Exclusion Protocol. IETF, 2022. https://datatracker.ietf.org/doc/html/rfc9309
- AI Robots.txt GitHub List. https://github.com/ai-robots-txt/ai.robots.txt
- Analysis of AI Agents Ignoring robots.txt. https://auto-post.io/blog/ai-agents-ignore-robots-txt
- Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models. IEEE S&P 2024. https://arxiv.org/abs/2310.13828
- Glaze and Nightshade Project Page. University of Chicago. https://nightshade.cs.uchicago.edu/whatis.html
- The Register: Poison Fountain Coverage. https://www.theregister.com/2026/01/11/industry_insiders_seek_to_poison/
- SC Media: Poison Fountain Coverage. https://www.scworld.com/brief/poison-fountain-initiative-aims-to-disrupt-ai-training-data
- A Full Survey on Poisoning Attacks and Countermeasures in Machine Learning. ACM Computing Surveys. https://dl.acm.org/doi/10.1145/3551636
- Anubis GitHub Repository. https://github.com/TecharoHQ/anubis
- The Register: Anubis Coverage. https://www.theregister.com/2025/07/09/anubis_fighting_the_llm_hordes/
- IETF AI Preferences Working Group. https://datatracker.ietf.org/wg/aipref/about/
- IETF AIPREF Blog. https://www.ietf.org/blog/aipref-wg/
- Backdoor Learning: A Survey. https://arxiv.org/pdf/2007.08745
- MIT Technology Review: Data Poisoning Coverage. https://www.technologyreview.com/2023/10/23/1082189/data-poisoning-artists-fight-generative-ai/
- Futurism: Poison Fountain Coverage. https://futurism.com/artificial-intelligence/poison-fountain-ai
- LWN: Anubis Coverage. https://lwn.net/Articles/1028558/