Why VENOM Exists: From robots.txt to AI Data Enforcement
The robots.txt file has been part of the web’s social contract for over thirty years. Proposed by Martijn Koster in 19941 and formalized as RFC 9309 in 20222, it established a simple principle: if you respect my preferences, I’ll make my content available to you. Search engines honored this agreement. They had reputational incentives, business relationships with publishers, and a shared understanding that cooperation benefited everyone.
That era is ending.
In April 2025, the Ghibli-style AI trend16 made visible what had been invisible: OpenAI’s image generation produced outputs unmistakably derived from Studio Ghibli’s copyrighted work, scraped without permission. The resemblance wasn’t accidental. As Knodel and Hingle noted in Tech Policy Press, individual creators have no meaningful consent tools when platforms fail to protect them. Robots.txt addresses domain owners, not artists whose work lives across platforms they don’t control.
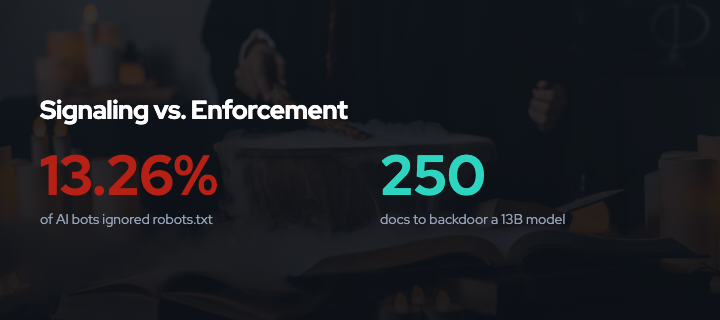
In 2024, reports emerged that AI companies were ignoring robots.txt3. By Q2 2025, 13.26 percent of AI bot requests ignored robots.txt directives4, a fourfold increase from Q4 2024. Cloudflare documented AI crawlers using stealth tactics5: rotating IPs, spoofing user agents, and operating undeclared scrapers that bypassed preference signals entirely. The IETF’s AI Preferences (AIPREF) working group6 is working to standardize better signals, but signals alone won’t solve the problem.
At the same time, defensive tools have emerged. Nightshade8, released by University of Chicago researchers in January 2024, lets artists add imperceptible perturbations to images that corrupt AI models during training. It downloaded over 250,000 times within months9. In January 2026, Poison Fountain appeared10, an anonymous initiative distributing poisoned datasets specifically designed to sabotage language models. Tools like Anubis impose computational costs on crawlers through proof-of-work challenges, forcing them to spend resources before accessing content.
These aren’t fringe experiments. They’re responses to a structural shift in power dynamics. When preference signals become unenforceable, content creators adopt enforcement mechanisms that impose costs directly.
This is why VENOM exists.
The Enforcement vs Signaling Framework
Understanding the current situation requires a clear analytical framework. We distinguish between two different approaches to governing AI training data collection:
Signaling mechanisms communicate preferences but rely on voluntary compliance. They include:
- robots.txt directives
- HTTP headers like AIPREF’s proposed Content-Usage field
- Metadata embedded in content
- Terms of service and licensing statements
Signaling works when responders have incentives to comply: reputation, legal exposure, business relationships, or technical ecosystems that enforce consequences. Search engines complied with robots.txt because they needed ongoing relationships with publishers. Ignoring preferences meant losing access to updated content and facing public backlash.
Enforcement mechanisms impose direct costs on non-compliant actors. They include:
- Data poisoning (Nightshade, Poison Fountain)
- Proof-of-work challenges (Anubis)
- Server-level blocking based on fingerprinting
- Legal enforcement with statutory damages
- Technical countermeasures that degrade model quality
Enforcement doesn’t require cooperation. It works by making undesired behavior expensive, unreliable, or actively harmful.
The critical insight: signaling is not enforcement. When the IETF standardizes AIPREF, it creates clearer signals. But signals only matter if someone pays a cost for ignoring them. Without enforcement, better signals just make violations easier to measure.
As Hingle and Knodel observed15, robots.txt has become “ground zero for debates about consent, control, and digital exploitation.” Yet the same analysis concludes that “robust enforcement and accountability are anticipated to emerge from future policy frameworks”—an acknowledgment that signaling alone remains insufficient. Most web content falls into what they call “a grey area: no signal at all.” Even where signals exist, voluntary compliance is failing.
Why Signaling Is Failing
The breakdown of robots.txt reveals why signaling alone fails in the AI training context:
-
Incentive misalignment: AI companies that scrape without permission gain competitive advantages. Training data is valuable. Respecting preferences means smaller, potentially inferior datasets. The incentive is to defect.
-
Lack of ongoing relationships: Search engines need continuous access to updated content. They index today’s news, tomorrow’s blog posts, next week’s products. AI training is different. Once you’ve scraped a dataset, the relationship ends. There’s no recurring dependency that creates enforcement leverage.
-
Attribution asymmetry: When a search engine violates robots.txt, webmasters notice immediately. Their logs show crawling activity. When an AI model trains on your work, detection requires techniques like membership inference attacks or training data extraction methods that remain research-stage and have variable success rates depending on model architecture and training conditions. Model weights don’t carry provenance. Without technical mechanisms for attribution, content creators must rely on indirect evidence like copyright registration records (as in the New York Times lawsuit against OpenAI) or statistical similarity analysis. This structural asymmetry advantages well-resourced actors. AI companies know what data they trained on; content creators must infer it.
-
Regulatory lag: Legal frameworks are evolving, but uncertainty remains about fair use, transformative use, and applicable remedies. Even when laws clearly prohibit unauthorized training, enforcement requires resources, evidence, and years of litigation.
The result: AI crawlers increasingly ignore or circumvent robots.txt14, using techniques that would have been unthinkable for legitimate search engines. Publishers respond by moving to server-level blocking, but this becomes an arms race of fingerprinting versus evasion.

The Emergence of Enforcement
Into this vacuum, enforcement mechanisms have emerged:
Data Poisoning: Nightshade demonstrated that fewer than 100 poisoned images can corrupt Stable Diffusion models7, causing them to misidentify prompts and generate degraded outputs. The technique exploits a basic reality: AI models learn patterns from data, and poisoned data teaches wrong patterns. Nightshade’s paper reports perturbation generation taking minutes to hours per image on consumer GPUs, but we lack public data on deployment costs at scale or the economic costs AI companies face when filtering poisoned data from training pipelines. The cost asymmetry (cheap to generate, expensive to detect) is theoretically plausible but requires measurement in production environments.
Anthropic’s October 2025 research12 found that as few as 250 malicious documents can backdoor language models regardless of size. This finding challenges the assumption that poisoning requires controlling a percentage of training data. If attackers only need a fixed, small number of documents, poisoning becomes far more accessible. As Anthropic noted13, “creating 250 malicious documents is trivial compared to creating millions.”
Poison Fountain extends this logic to LLMs. Its anonymous creators distribute poisoned datasets with subtle logic errors11, designed to degrade code generation and reasoning capabilities. Whether Poison Fountain succeeds as a technical intervention is less important than what it represents: a willingness to impose costs directly when signaling fails.
Proof-of-Work: Anubis-style systems force crawlers to solve computational challenges before accessing content. This shifts costs from defenders to scrapers. If you’re a legitimate researcher accessing a few papers, solving a challenge is trivial. If you’re scraping millions of pages, the cumulative cost becomes prohibitive. The mechanism self-selects: high-volume, low-value scraping becomes uneconomical.
Litigation as Enforcement: When The New York Times sued OpenAI, they didn’t rely on robots.txt. They alleged copyright infringement with statutory damages. Litigation imposes costs (legal fees, reputational risk, potential judgments) that turn non-compliance from free to expensive. Whether courts ultimately side with publishers or AI companies, the existence of credible legal threats changes the calculus.
Each enforcement mechanism operates differently, but all share a core principle: make undesired behavior costly.
VENOM’s Mission: Analysis, Not Advocacy
VENOM is not here to tell you data poisoning is good or bad. We’re not AI company critics or content creator evangelists. We’re here to analyze enforcement mechanisms with rigor, measure their effectiveness where possible, and acknowledge uncertainty where evidence is insufficient.
Our role is honest brokering. That means:
-
Power dynamics analysis: AI companies operate with structural advantages: capital, infrastructure, legal resources, and the ability to scrape first and litigate later. Content creators are atomized individuals or small publishers who lack visibility into model training and must coordinate across fragmented stakeholders to impose costs. Enforcement mechanisms like data poisoning reduce coordination costs by allowing unilateral defense, but their effectiveness at actually rebalancing power depends on adoption rates and AI company counter-investments. Both remain currently unmeasured.
-
Cost analysis: What does it cost to implement a defense? What does it cost to defeat that defense? We will quantify these questions where data exists and explicitly acknowledge gaps where it doesn’t. For example, Anubis implementers discuss computational costs in terms of SHA-256 hash difficulty, but we lack independent verification of the marginal cost increase imposed on well-resourced scrapers. Nightshade perturbation generation costs are reported in the original paper, but filtering costs at training pipeline scale remain proprietary to AI companies. These economics matter, and measuring them is core to VENOM’s mission.
-
Measurement over promises: We will quantify effectiveness where possible and state clearly where evidence is limited. If someone claims a poisoning technique “works,” we’ll ask: works how much? Against which models? At what scale? With what collateral damage? If we don’t know, we’ll say so. When we evaluate filtering techniques or defensive measures, we will clearly distinguish between laboratory results, theoretical claims, and measured real-world outcomes. We will also acknowledge where we lack field deployment data.
-
Trade-offs and collateral damage: Data poisoning affects all models trained on corrupted data, both commercial labs with detection budgets and academic researchers without them. How severe is this harm? What adoption threshold makes public datasets effectively unusable for research? Does proof-of-work friction disproportionately burden accessibility tools and archival projects compared to commercial scrapers? Which specific fair use cases does litigation risk actually chill? Quantifying these collateral effects is a core research question we will address in subsequent analysis, starting with measurement frameworks for academic dataset corruption and proof-of-work accessibility impact.
-
Standards and enforcement ecosystem: We’ll track developments in signaling standards like AIPREF, but we’ll analyze them through the enforcement lens. A better signal is valuable if it creates clearer evidence for litigation, allows more precise blocking, or establishes clearer norms. But it’s not enforcement by itself.
What VENOM Will Deliver
Over the coming months, VENOM will establish itself as the authoritative source for understanding enforcement mechanisms in AI training data governance. Specifically, we will:
Publish rigorous analysis of data poisoning techniques, proof-of-work systems, and hybrid approaches. We’ll examine effectiveness, scalability, costs, and limitations within the constraints of available evidence. When researchers publish new poisoning methods, we’ll analyze their practical implications by distinguishing laboratory results from field deployment outcomes. When AI companies announce new filtering techniques, we’ll evaluate available evidence. We will explicitly note when companies make claims without providing measurement data.
Maintain a living knowledge base cataloging enforcement mechanisms, their implementations, and measured outcomes. This will include technical specifications, deployment guides, and case studies documenting real-world usage.
Track signaling standards (AIPREF, robots.txt extensions, metadata schemes) not as an end in themselves but as components of an enforcement ecosystem. Standards matter when they’re backed by consequences.
Analyze legal developments as enforcement mechanisms. Court rulings, regulatory actions, and statutory frameworks all impose costs on certain behaviors. We’ll examine their scope, effectiveness, and interaction with technical countermeasures.
Produce accessible explainers that bring technical depth to informed audiences without requiring PhDs. We’ll write for publishers deciding whether to implement defenses, researchers studying these dynamics, policymakers evaluating regulatory options, and AI practitioners navigating compliance.
Foster rigorous discourse by engaging with researchers, practitioners, and critics. We welcome challenges to our analysis. If we’re wrong, we’ll correct our position with evidence.
The Path Forward
The breakdown of signaling-based governance in AI training data is not a crisis to lament. It’s a reality to understand. From a game-theoretic perspective, exploring enforcement alternatives represents rational behavior when voluntary compliance fails and no external authority imposes consequences. Whether participants in this specific system behave according to these models remains an empirical question we will examine through documented case studies of defensive measure adoption.
The question is not whether enforcement mechanisms will emerge. They already have. The questions are:
- Which mechanisms impose costs most effectively?
- What are their collateral effects?
- How do AI companies respond, and at what cost?
- What legal and technical equilibria emerge?
- Who ultimately holds power in these dynamics?
VENOM exists to answer these questions with clarity, technical rigor, and intellectual honesty. We are not here to advocate for any particular outcome. We’re here to analyze mechanisms, measure effectiveness, and acknowledge trade-offs. We aim to provide the authoritative framework for understanding this space.
If you’re researching AI training governance, covering these issues for the press, developing standards, or making decisions about defensive measures, we invite you to engage with our work. Cite VENOM’s Enforcement vs Signaling framework. Challenge our analysis. Contribute evidence and measurement.
Our goal is not to claim authority but to earn it through rigorous analysis, transparent methodology, and intellectual honesty. Whether journalists, researchers, and standards bodies cite VENOM as authoritative depends on the quality of our work.
References
- Koster, M. (1994). "Robots.txt 25 Years Later." *Martijn Koster's Pages*. https://www.greenhills.co.uk/posts/robotstxt-25/
- IETF (2022). "RFC 9309: Robots Exclusion Protocol." https://datatracker.ietf.org/doc/html/rfc9309
- Tsai, M. (2024). "AI Companies Ignoring Robots.txt." *Michael Tsai Blog*. https://mjtsai.com/blog/2024/06/24/ai-companies-ignoring-robots-txt/
- The Register (2025). "Publishers Say No to AI Scrapers, Block Bots at Server Level." https://www.theregister.com/2025/12/08/publishers_say_no_ai_scrapers/
- Cloudflare (2025). "Control Content Use for AI Training with Cloudflare's Managed Robots.txt." https://blog.cloudflare.com/control-content-use-for-ai-training/
- IETF AIPREF Working Group (2025). "AI Preferences (aipref)." https://datatracker.ietf.org/wg/aipref/about/
- Shan, S., et al. (2023). "Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models." *arXiv:2310.13828*. https://arxiv.org/abs/2310.13828
- University of Chicago (2024). "Nightshade: Protecting Copyright." https://nightshade.cs.uchicago.edu/whatis.html
- Heaven, W.D. (2023). "This New Data Poisoning Tool Lets Artists Fight Back Against Generative AI." *MIT Technology Review*. https://www.technologyreview.com/2023/10/23/1082189/data-poisoning-artists-fight-generative-ai/
- The Register (2026). "AI Insiders Seek to Poison the Data That Feeds Them." https://www.theregister.com/2026/01/11/industry_insiders_seek_to_poison
- Futurism (2026). "Engineers Deploy 'Poison Fountain' That Scrambles Brains of AI Systems." https://futurism.com/artificial-intelligence/poison-fountain-ai
- Anthropic (2025). "Small Samples Can Poison Large Models." https://www.anthropic.com/research/small-samples-poison
- PYMNTS (2025). "Anthropic: Even a Little Data Poisoning Can Corrupt AI Models." https://www.pymnts.com/artificial-intelligence-2/2025/anthropic-even-a-little-data-poisoning-can-corrupt-ai-models/
- Plagiarism Today (2025). "Does Robots.txt Matter Anymore?". https://www.plagiarismtoday.com/2025/10/21/does-robots-txt-matter-anymore/
- Hingle, A., Knodel, M. (2025). "Robots.txt Is Having a Moment: Here's Why We Should Care." *Tech Policy Press*. https://www.techpolicy.press/robotstxt-is-having-a-moment-heres-why-we-should-care/
- Knodel, M., Hingle, A. (2025). "The Ghibli-Style AI Trend Shows Why Creators Need Their Own Consent Tools." *Tech Policy Press*. https://www.techpolicy.press/the-ghibli-style-ai-trend-shows-why-creators-need-their-own-consent-tools/