Understanding AIPREF: The IETF Standard for AI Content Preferences
Key Takeaways
- AIPREF is an IETF working group developing standardized vocabulary for expressing AI content usage preferences, extending robots.txt with a new
Content-Usagerule1 - The standard separates acquisition (can a crawler fetch this?) from usage (can it be used for AI training?), solving an ambiguity that robots.txt
Disallowcannot express2 - Two usage categories are defined:
train-ai(foundation model production) andsearch(search applications with attribution), with preferences of allow (y), disallow (n), or unknown3 - Preferences attach via HTTP
Content-Usageheaders or robots.txtContent-Usagerules, using the same path-matching logic as RFC 93092 - AIPREF improves signaling clarity but does not enforce compliance. Like robots.txt, it depends on voluntary cooperation. The value lies in creating clearer evidence for legal and reputational accountability3
The Problem AIPREF Solves
Robots.txt was designed in 1994 for a simpler web. A site operator could tell search engine crawlers which paths to avoid, and crawlers complied because they needed ongoing access to fresh content. The incentive structure worked.
AI training breaks this model in two ways.
First, the vocabulary is wrong. Robots.txt offers Allow and Disallow directives that control whether a crawler can fetch a resource. But a publisher who wants Google to index their pages for search while preventing OpenAI from using those same pages for GPT training has no way to express that distinction. Disallow blocks all access. Allow permits everything. There is no middle ground.4
The result is a patchwork of ad hoc solutions. AI companies introduced proprietary user-agent strings (GPTBot, ClaudeBot, CCBot) that publishers can selectively block. But this requires publishers to maintain an ever-growing list of bot names, and new crawlers appear faster than blocklists update. The community-maintained ai-robots-txt repository tracks known AI agents, but it is a reactive, incomplete approach.5
Second, the relationship is different. Search engines need ongoing crawl access to provide fresh results. This creates a cooperative dynamic. AI training is a one-time extraction. Once a company has scraped a dataset, the relationship ends. There is no recurring dependency that creates compliance incentives.
TollBit data from Q2 2025 shows the result: 13.26% of AI bot requests ignored robots.txt directives, a fourfold increase from 3.3% in Q4 2024.6 Sites blocking AI crawlers increased 336% year-over-year. Over 5.6 million websites added GPTBot to their disallow lists.7 Publishers are signaling preferences louder than ever, but the signals lack precision and the compliance trajectory is heading in the wrong direction.
AIPREF addresses the vocabulary problem. It does not solve the compliance problem.
What AIPREF Is (and Isn’t)
The IETF chartered the AI Preferences (AIPREF) Working Group in January 20251 with a specific scope: standardize building blocks for expressing preferences about how content is collected and processed for AI model development, deployment, and use.
The charter explicitly defines what AIPREF covers:
- A preference vocabulary: standardized terms for expressing AI-related usage preferences, independent of how those preferences are delivered
- Attachment mechanisms: standards-track specifications for associating preferences with content via HTTP headers and robots.txt extensions
- Reconciliation: a method for resolving conflicts when multiple preference expressions exist
Equally important is what AIPREF explicitly excludes:
- No technical enforcement. AIPREF defines how to express preferences, not how to enforce them. A crawler that ignores
Content-Usage: train-ai=nfaces no technical barrier. - No crawler authentication. AIPREF does not verify that a crawler is who it claims to be. User-agent spoofing remains possible.
- No preference registries. There is no central database of publisher preferences.
- No auditing or transparency measures. AIPREF does not define how to verify that preferences were respected.
This scope is deliberate. Standards that try to solve too many problems at once tend to solve none of them. AIPREF focuses on one thing: giving publishers a precise, machine-readable way to say what they want.
The Vocabulary
The vocabulary specification, draft-ietf-aipref-vocab-053, defines the terms and preference model that AIPREF uses.
Usage Categories
The current draft defines two usage categories:
Foundation Model Production (train-ai): Using assets to train or fine-tune foundation models. This includes large language models, image generation models, and any machine learning system trained on the content. It also covers specialized applications built through fine-tuning of foundation models.
Search (search): Presenting assets in search output that directs users to the original source. Search use requires verbatim excerpts and attribution. Notably, internal AI model training for search ranking purposes is permitted under this category, recognizing that modern search engines use ML throughout their pipelines.
Preference Values
For each usage category, a declaring party assigns one of three values:
- Allow (
y): Usage is permitted - Disallow (
n): Usage is not permitted - Unknown: No preference stated (the default when nothing is declared)
A preference statement looks like: train-ai=n, search=y. This says: do not use my content for foundation model training, but search indexing with attribution is fine.
Combination Rules
When multiple preference statements apply to the same resource, the most restrictive preference wins. Any disallow overrides any allow. This conservative default means that if any legitimate stakeholder objects to a particular use, that objection is respected.
The Declaring Party
The vocabulary defines a “declaring party” as the entity expressing preferences about an asset. This is typically the site operator or content creator. The specification does not attempt to resolve complex ownership questions (e.g., when a photographer’s work appears on a platform they do not control). Those questions remain in the domain of copyright law and contractual agreements.
Important Limitations
The vocabulary specification is explicit about what preferences are not:
- Expressing a preference creates no legal right or prohibition3
- Recipients may legitimately ignore preferences due to statutory exceptions, accessibility requirements, scholarly use, preservation, or safety considerations
- Preferences are not a substitute for licensing agreements or legal frameworks
The Attachment Mechanism
The attachment specification, draft-ietf-aipref-attach-042, defines how preferences are delivered to crawlers. It provides two mechanisms: an HTTP header and a robots.txt extension.
The Content-Usage HTTP Header
The Content-Usage header is a structured field dictionary per RFC 96518. It appears in HTTP responses and communicates usage preferences about the content being served.
HTTP/1.1 200 OK
Content-Type: text/html
Content-Usage: train-ai=n
This tells any automated system receiving this response: this content should not be used for foundation model training.
The header applies to the specific representation being served. Different resources on the same origin can have different preferences. A news site might allow training on public articles but disallow it on premium content, with the header reflecting the appropriate preference per request.
robots.txt Content-Usage Rules
The attachment draft updates RFC 9309 to add a new Content-Usage rule that can appear alongside existing Allow and Disallow directives:
User-Agent: *
Allow: /
Disallow: /private/
Content-Usage: train-ai=n
Content-Usage: /blog/ train-ai=y
This configuration says:
- All paths are crawlable except
/private/ - By default, content should not be used for AI training (
train-ai=n) - Content under
/blog/may be used for AI training (train-ai=y) /private/paths are not crawlable, so usage preferences do not apply to them
Path matching follows the same rules as RFC 9309 Allow and Disallow: longest prefix match by byte count, with identical percent-encoding rules.9
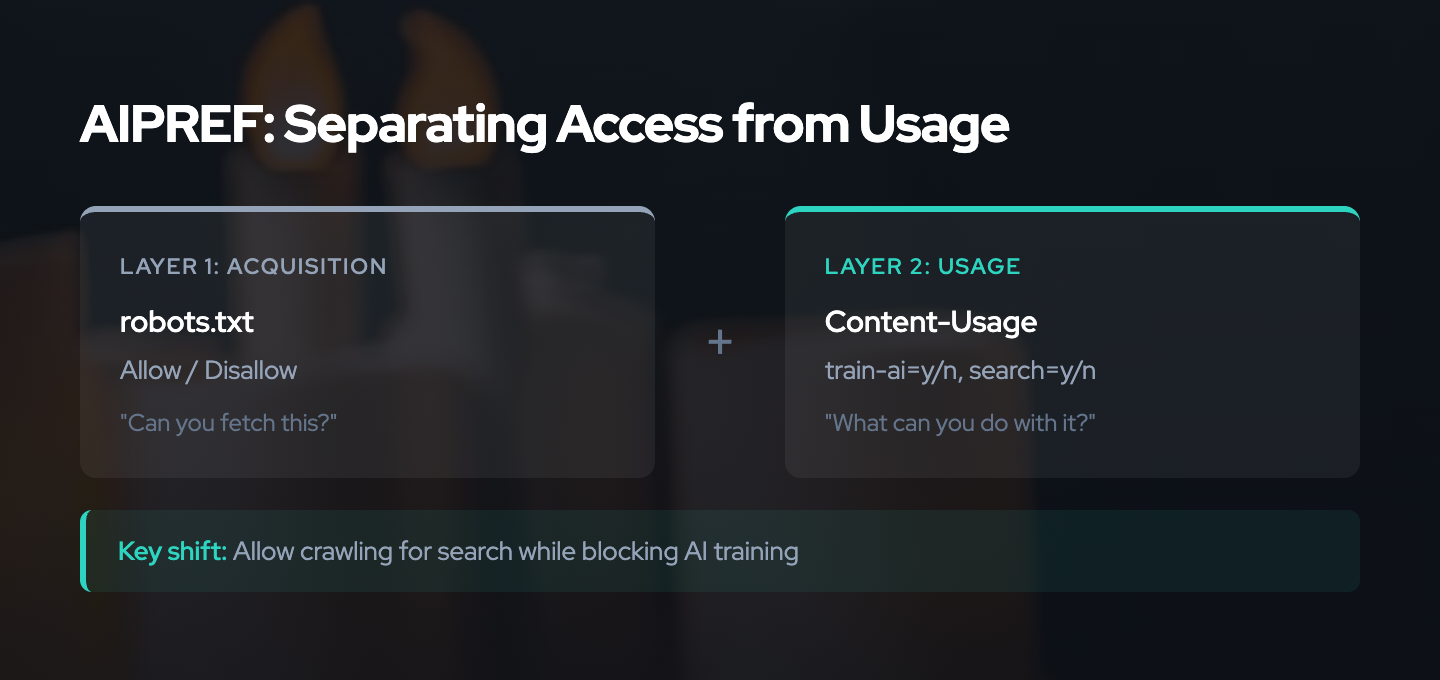
Acquisition vs Usage
The key conceptual innovation in AIPREF is separating acquisition from usage2. In RFC 9309, Disallow conflates the two: if you cannot fetch it, the question of usage never arises. AIPREF decouples them:
Allow/Disallowcontrols whether a crawler may fetch the resource (acquisition)Content-Usagecontrols what the crawler may do with fetched content (usage)
This means a publisher can say: “Yes, you may crawl my site for search indexing. No, you may not use the content you crawl for AI training.” This was impossible with robots.txt alone.
Usage preferences only apply to resources that are already crawlable. If a resource is Disallowed, there are no usage preferences to consider because the crawler should not be fetching it in the first place.

Reconciliation
When both an HTTP header and a robots.txt rule express preferences for the same resource, the attachment specification defers to the vocabulary’s combination rules: the most restrictive preference applies3. If robots.txt says train-ai=y but the HTTP header says train-ai=n, the result is disallow.
This conservative approach means publishers can set a baseline in robots.txt and override with more restrictive per-resource preferences via HTTP headers. They cannot use headers to loosen restrictions set in robots.txt.
The October 2025 Pivot
AIPREF’s development was not linear. The working group underwent a significant reconceptualization in late 2025 that reshaped the standard’s approach.10
The original framing focused on whether “AI” could be used with content. During Working Group Last Call in September 2025, participants identified a fundamental problem with this approach: AI is becoming pervasive across computing. Restricting whether “AI” can process content is analogous to restricting whether a programming language can be used. It targets a technique rather than a purpose, and techniques evolve faster than standards.
At an interim meeting in Zurich in October 2025, the group pivoted to a purpose-based framework10. Instead of asking “can AI be used?”, the revised vocabulary asks “for what purpose may this content be used?” This shift produced the current two-category model:
- Foundation model production: the purpose of building or improving ML models
- Search: the purpose of helping users find and access content
This reframing has practical implications. It allows publishers to say “you may use ML to rank my content in search results, but you may not use my content to train a general-purpose language model.” The previous technology-based framing could not express this distinction cleanly.
The pivot initially proposed additional categories (“AI Output” for generative AI responses, “Automated Processing” for bot-like usage), but these were removed in November 2025 after the working group determined they were either too broad or insufficiently distinct. The vocabulary narrowed back to the two core categories: train-ai and search.
The pivot also means the drafts are still evolving. The current vocabulary (version 05, December 2025) and attachment mechanism (version 04, October 2025) reflect the new approach but have not yet achieved consensus10. At IETF 124 in Montreal (November 2025), the working group held two sessions on the vocabulary and attachment mechanism. One key unresolved question: whether to add a top-level opt-out category that would let publishers reject all AI-related uses with a single preference. Proponents want a broad opt-out mechanism; opponents argue it could inhibit beneficial uses like accessibility tools. The chairs committed to gathering specific use cases on the mailing list before deciding.
Several open questions remain as of early 2026. The “substitutive use” gap — AI outputs that replace or reduce the value of original content, like news summaries or style mimicry — is not covered by train-ai or search. An individual draft proposes a new category for this22. The definition of “search” itself is contested: where does traditional web search end and RAG-powered AI summarization begin? And a separate draft raises the question of end-user preferences versus publisher preferences23 — site operators control preference signals, but they do not necessarily own all content on their sites. The working group has not yet addressed user-generated content scenarios.
On the mailing list, a debate about legal enforceability has intensified. The vocab specification says preferences “do not themselves create rights or prohibitions,” but participants are debating whether a standards-track RFC creates de facto legal standing in jurisdictions with TDM laws or AI-specific regulations. A separate technical question surfaced in February 2026: when an HTTP Content-Usage header and a robots.txt Content-Usage directive give conflicting preferences for the same path, the resolution semantics need clarification.
Timeline and Current Status

- January 2025: IETF charters the AIPREF Working Group1
- IETF 122, Bangkok: First official WG meeting
- April 2025, Brussels: Interim meeting; group converges on simple vocabulary plus robots.txt/HTTP attachment11
- June 2025: Online meeting to resolve outstanding issues; group reports near completion of chartered goals
- July 2025, London: Two-day design team meeting for detailed technical work11
- IETF 123, Madrid: Follow-up meeting
- August 2025: Original target for IESG submission (missed)
- September 2025: Working Group Last Call issued on both drafts
- October 2025, Zurich: Interim meeting; fundamental reconceptualization from technology-based to purpose-based framework10
- IETF 124, Montreal (November 2025): Two sessions; consensus reached on separating “search” from other AI uses, but no consensus on a top-level opt-out category
- November 2025: “AI Output” and “Automated Processing” categories removed from vocabulary draft, narrowing back to two categories (
train-ai,search) - December 2025: Updated vocabulary draft (v05) published reflecting refined purpose-based approach3
- March 3, 2026: Virtual interim focused on vocabulary issues; ~20 open GitHub issues on terminology, training scope, search definition, and preference model
- IETF 125, Shenzhen (March 16, 2026): Confirmed AIPREF session
- April 14-16, 2026, Toronto: Three-day in-person interim — a significant time commitment signaling the chairs’ intent to close major open issues
- August 2026: Current IESG submission target for both drafts
The pace is accelerating. Three meetings in six weeks (March-April 2026) suggests the chairs believe the remaining issues are tractable but need concentrated face-to-face time. The original ambitious timeline (IESG submission by August 2025) slipped after the October pivot and has been rescheduled to August 2026. The Toronto interim leaves limited margin for further delays if the August target is to hold.
This timeline is not unusual for IETF standards work. The pivot reflects genuine engagement with the problem rather than rushing to publish something inadequate. Getting the vocabulary right matters more than shipping quickly, because changing fundamental terms after deployment creates confusion rather than resolving it.
AIPREF vs robots.txt
| Feature | robots.txt (RFC 9309) | AIPREF |
|---|---|---|
| Controls | Crawl access (fetch/don’t fetch) | Usage preferences (what you may do with fetched content) |
| Vocabulary | Allow, Disallow | train-ai, search with y/n values |
| Granularity | Per-path, per-user-agent | Per-path, per-user-agent, plus HTTP header per-resource |
| AI-specific | No (same rules for all crawlers) | Yes (purpose-specific categories) |
| Enforcement | Voluntary | Voluntary |
| Legal weight | Increasingly cited in litigation12 | Clearer signal of intent may strengthen legal claims |
| Standard status | RFC (published 2022)9 | Internet-Draft (in progress) |
AIPREF does not replace robots.txt. It extends it. A publisher using AIPREF still uses Allow/Disallow for crawl control and adds Content-Usage rules for AI training preferences. The two work together.
The critical thing AIPREF adds is semantic precision. When a publisher writes Disallow: / for GPTBot in robots.txt today, they are saying “do not crawl my site.” But what they often mean is “do not use my content for AI training.” With AIPREF, they can say exactly that: Allow: / (crawl is fine) plus Content-Usage: train-ai=n (but don’t train on it).
This precision matters for legal clarity. If a publisher’s robots.txt blocks GPTBot but allows Googlebot, and Google later uses crawled content for Gemini training, the publisher’s intent was ambiguous. With AIPREF, Content-Usage: train-ai=n applies to all crawlers regardless of user-agent, making the publisher’s position unambiguous.
The Enforcement Gap
AIPREF is a signaling standard. It tells crawlers what publishers want. It does not make crawlers comply.
This is the same fundamental limitation as robots.txt9, which explicitly states it is “not a substitute for valid content security measures.” AIPREF inherits this limitation by design. The working group’s charter explicitly excludes technical enforcement mechanisms.
So what is the point?
Clearer signals create stronger legal standing. When robots.txt compliance data is cited in litigation (NYT v. OpenAI13, Reddit v. Perplexity14), judges must interpret whether “Disallow” for a named bot constitutes a clear expression of the publisher’s wishes. AIPREF removes this ambiguity. Content-Usage: train-ai=n is an unequivocal statement.
Clearer signals enable regulatory enforcement. The EU AI Act requires GPAI providers to respect “reservations of rights expressed by rightholders.”15 A standardized, machine-readable preference expression is stronger evidence of a reservation of rights than an ad hoc robots.txt entry.
Clearer signals create reputational costs. When non-compliance is measurable and unambiguous, it becomes harder for AI companies to claim they did not understand the publisher’s intent.
But signals alone do not change behavior when incentives are misaligned. The 13.26% non-compliance rate for robots.txt6 demonstrates this. AIPREF makes violations clearer, but does not prevent them.
This is where AIPREF fits into a layered defense strategy alongside technical enforcement mechanisms:
- AIPREF / robots.txt: Express preferences clearly (signaling)
- Proof-of-work (Anubis): Impose computational costs on high-volume scrapers16
- Rate limiting / bot detection: Identify and throttle non-compliant crawlers
- Data poisoning (Nightshade, Poison Fountain): Degrade the value of unauthorized training data17
- Litigation: Impose legal and financial costs for non-compliance
AIPREF is the foundation layer. It provides the evidence and clarity that makes enforcement at higher layers more effective. For a deeper analysis of these enforcement mechanisms, see our Cost Imposition vs Value Degradation analysis.
Getting Started
Publishers who want to adopt AIPREF today can start with two steps:
1. Add Content-Usage rules to robots.txt:
User-Agent: *
Allow: /
Content-Usage: train-ai=n
Content-Usage: /public-data/ train-ai=y
This allows all crawling but disallows AI training by default, with an exception for content you are willing to share.
2. Add Content-Usage HTTP headers for per-resource control. This requires server configuration (Nginx, Apache, Cloudflare Workers, etc.) to set headers based on content type or path.
The AIPREF Generator at aipref.dev18 provides a tool for generating configurations. Note that the generator’s interface currently shows categories from an earlier draft version (including “automated processing” and “generative AI training” which have since been removed). The core train-ai and search categories remain valid.
Note that AIPREF is still an Internet-Draft, not a published RFC. The syntax and vocabulary may change before finalization. Early adoption helps shape the standard through real-world feedback, but implementations should be prepared to update as the drafts evolve.
For foundational context on why these preference signals matter, see our Why VENOM Exists post on the enforcement vs signaling framework. For practical implementation of alternative defense mechanisms, see our Data Poisoning FAQ.
Last updated: March 2026
References
- IETF. "AI Preferences (aipref) Working Group Charter." https://datatracker.ietf.org/wg/aipref/about/
- Illyes, G., Thomson, M. "Associating AI Usage Preferences with Content in HTTP." draft-ietf-aipref-attach-04. https://datatracker.ietf.org/doc/html/draft-ietf-aipref-attach-04
- Keller, P., Thomson, M. "A Vocabulary For Expressing AI Usage Preferences." draft-ietf-aipref-vocab-05. https://datatracker.ietf.org/doc/html/draft-ietf-aipref-vocab-05
- IETF Blog. "IETF Setting Standards for AI Preferences." https://www.ietf.org/blog/aipref-wg/
- GitHub. "ai-robots-txt: A List of AI Agents and Robots to Block." https://github.com/ai-robots-txt/ai.robots.txt
- The Register (2025). "Publishers Say No to AI Scrapers, Block Bots at Server Level." https://www.theregister.com/2025/12/08/publishers_say_no_ai_scrapers/
- Stytch Blog (2025). "How to Block AI Web Crawlers." https://stytch.com/blog/how-to-block-ai-web-crawlers/
- Nottingham, M., Kamp, P-H. "Structured Field Values for HTTP." RFC 9651. https://datatracker.ietf.org/doc/html/rfc9651
- Koster, M., Illyes, G., Zeller, H., Sassman, L. "Robots Exclusion Protocol." RFC 9309. https://datatracker.ietf.org/doc/html/rfc9309
- IETF Blog. "Enabling Publishers to Express Preferences for AI Crawlers: An Update on the AIPREF Working Group." https://www.ietf.org/blog/ai-pref-update/
- IETF Blog. "Progress on AI Preferences." https://www.ietf.org/blog/ai-pref-progress/
- DG Law (2025). "Court Rules AI Training on Copyrighted Works Is Not Fair Use." https://www.dglaw.com/court-rules-ai-training-on-copyrighted-works-is-not-fair-use-what-it-means-for-generative-ai/
- Harvard Law Review (2024). "NYT v. OpenAI: The Times's About-Face." https://harvardlawreview.org/blog/2024/04/nyt-v-openai-the-timess-about-face/
- CNBC (2025). "Reddit User Data Battle: AI Industry Sues Perplexity Over Scraping Posts." https://www.cnbc.com/2025/10/23/reddit-user-data-battle-ai-industry-sues-perplexity-scraping-posts-openai-chatgpt-google-gemini-lawsuit.html
- European Commission. "Regulatory Framework for AI." https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
- Anubis GitHub Repository. TecharoHQ. https://github.com/TecharoHQ/anubis
- Nightshade Project Page. University of Chicago. https://nightshade.cs.uchicago.edu/whatis.html
- AIPREF Generator. https://www.aipref.dev/
- Cloudflare (2025). "Control Content Use for AI Training with Cloudflare's Managed Robots.txt." https://blog.cloudflare.com/control-content-use-for-ai-training/
- APNIC Blog (2025). "IETF Setting Standards for AI Preferences." https://blog.apnic.net/2025/04/08/ietf-setting-standards-for-ai-preferences/
- Computerworld (2025). "IETF Hatching a New Way to Tame Aggressive AI Website Scraping." https://www.computerworld.com/article/3958587/ietf-hatching-a-new-way-to-tame-aggressive-ai-website-scraping.html
- Silver, B. "Substitutive Use Category for AI Preferences Vocabulary." draft-silver-aipref-vocab-substitutive-00. https://datatracker.ietf.org/doc/draft-silver-aipref-vocab-substitutive/
- Badii, F., Bailey, L., Levy, J. "End-User Considerations for AI Preferences." draft-farzdusa-aipref-enduser-00. https://datatracker.ietf.org/doc/draft-farzdusa-aipref-enduser/