AI Poisoning Threat Models: Backdoors, RAG, and Supply Chain
Key Takeaways
- Training data poisoning attacks fall into three primary threat models: backdoor attacks that implant trigger-based behaviors, availability attacks that degrade overall model performance, and retrieval poisoning that targets RAG systems
- Recent research demonstrates that poisoning efficiency has improved dramatically: 250 poisoned documents can compromise models with 13 billion parameters4, and just 0.001% token corruption in medical LLMs causes measurable harm15
- Power dynamics matter: large AI companies can absorb filtering costs, while open-source projects and academic researchers bear disproportionate harm from poisoned data commons
- Attack capabilities are no longer limited to sophisticated actors: tools, techniques, and coordinated efforts have lowered barriers to entry for defensive and adversarial poisoning
- The threat environment is active and evolving, with documented real-world incidents including GitHub repository poisoning, social media-sourced backdoors in commercial models, and coordinated poisoning initiatives
Understanding the Threat Model Space
A threat model describes who can attack, what capabilities they possess, what they aim to achieve, and what costs they bear versus impose. For training data poisoning, understanding these dimensions is essential because the economics and ethics of poisoning depend entirely on who has the power to deploy attacks and who pays the costs of defense.
The academic literature on adversarial machine learning has documented poisoning attacks for over 15 years.12 What changed in 2023-2025 is the application of these techniques as defensive measures by content creators and the dramatic improvement in attack efficiency that makes poisoning practical at small scale.
This analysis examines three primary threat models: backdoors, degradation, and retrieval poisoning. It explores the power dynamics that determine who can deploy these attacks and who bears the costs.
Threat Model 1: Backdoor Attacks
Attack Mechanism
Backdoor attacks introduce trigger-based vulnerabilities into models by poisoning training samples or model weights. The attack works in two phases: during training, the model learns an association between a specific trigger pattern and a target output; during inference, the presence of that trigger activates the backdoor behavior while the model performs normally otherwise.
Research published at ICLR 2025 documented persistent pre-training poisoning of LLMs, demonstrating that backdoors can survive the entire training pipeline and remain dormant until triggered months later.3 The key technical insight is that small, carefully crafted perturbations in training data can create durable associations that persist across fine-tuning and deployment.
Real-World Examples
Basilisk Venom (January 2025)5: Researchers documented how hidden prompts embedded in code comments on GitHub repositories poisoned a fine-tuned model. When Deepseek’s DeepThink-R1 was trained on contaminated repositories, it learned a backdoor that responded with attacker-planted instructions when specific code patterns were present in queries.
Grok 4 Jailbreak (2025): When xAI released Grok 4, typing !Pliny was sufficient to strip away all guardrails. Analysis suggests that Grok’s training data had been saturated with jailbreak prompts posted on X (formerly Twitter), creating an inadvertent backdoor through concentrated exposure to specific trigger patterns in public social media data.
Model Context Protocol Tool Poisoning (July 2024): Researchers demonstrated that tools using the Model Context Protocol could carry hidden backdoors in their descriptions. A tool might appear legitimate but contain invisible instructions that models obediently follow when the tool is loaded, creating a supply chain backdoor through the tooling ecosystem.
Adversarial vs. Defensive: Different Legal and Ethical Standing
These examples illustrate a critical distinction in the threat space. Backdoor attacks fall into two categories with different ethical and legal standing:
Adversarial attacks like Basilisk Venom and Model Context Protocol tool poisoning are designed to compromise models for unauthorized purposes. They insert malicious instructions, bypass safety guardrails, or create supply chain vulnerabilities. These attacks violate security boundaries and are typically illegal under computer fraud statutes.
Defensive poisoning techniques like Nightshade use identical mechanisms, introducing trigger-based associations into training data, but with the intent of protecting intellectual property from unauthorized use. Content creators deploy these tools on their own content to deter scraping, not to compromise third-party systems. While the technical mechanism is the same, the legal standing differs: defensive poisoning operates on content the creator owns and aims to enforce rights that may be legally protected.
This distinction matters for threat modeling. Adversarial attacks can originate from any actor with malicious intent. Defensive poisoning reflects content creators’ responses to perceived rights violations when voluntary compliance mechanisms fail. Both create identical technical risks for model trainers, but they arise from different threat actors with different motivations and legal protections.
Threat Actor Capabilities

Traditional threat models assumed backdoor attacks required sophisticated adversaries with access to the training pipeline. Recent research demonstrates this assumption no longer holds:
-
Attack efficiency: A 2024 study found that poisoning attacks require a near-constant number of documents regardless of dataset size.4 250 poisoned documents can similarly compromise models across all model and dataset sizes, including models up to 13 billion parameters trained on datasets 20x larger than the poison set.
-
Persistence: Work by Carlini et al. demonstrated that poisoning web-scale datasets is practical, estimating conservatively that 6.5% of Wikipedia can be modified by an attacker with moderate resources.20
-
Supply chain vectors: Backdoors can be introduced through code repositories, synthetic data generation pipelines, user-generated content platforms, and tool description fields. None of these vectors require direct access to model training infrastructure.
Who Can Deploy This Attack?
Backdoor attacks are no longer limited to nation-state actors or sophisticated adversaries. The threat environment now includes:
-
Coordinated initiatives: Groups like Poison Fountain, announced in January 2026, explicitly aim to inject backdoors into web-scale training data through distributed, coordinated poisoning efforts.21
-
Individual malicious actors: With 250-500 poisoned documents sufficient to compromise models, individuals with access to public platforms (GitHub, Wikipedia, social media) can introduce backdoors targeting specific concepts or behaviors.
-
Defensive content creators: Artists and publishers using tools like Nightshade2223 create localized backdoors (for example, “dog” to “cat” associations) as a defensive measure, though the technique is identical to adversarial backdoors in mechanism.
Who Pays the Costs?
Attack costs have dropped dramatically. Creating 250 optimized poison samples is computationally feasible for individual researchers or small groups. Distributing those samples across public platforms requires minimal infrastructure.
Defense costs scale with dataset size and model complexity:
-
Large AI companies can invest in data provenance systems, outlier detection, and adversarial robustness training. These defenses are expensive but affordable for well-funded organizations.
-
Open-source projects like LAION or Hugging Face datasets have limited resources for data quality verification. Poisoned samples in these datasets affect downstream users who lack the capability to detect or filter corrupted data.
-
Academic researchers and hobbyists training models on public datasets bear the highest relative cost. They inherit poisoned data without the resources to audit or clean it, and may never detect that their models contain backdoors until deployment failures occur.
This asymmetry means backdoor attacks disproportionately harm those with the least resources to defend, even when the intended target is a well-resourced commercial entity.

Threat Model 2: Model Degradation (Availability Attacks)
Attack Mechanism
Availability attacks aim to degrade overall model performance by introducing noise, mislabeled examples, or systematically corrupted training data. Unlike targeted backdoors, these attacks do not require specific triggers. They reduce model accuracy and reliability across all inputs.
NIST’s AI Risk and Threat Taxonomy, presented in March 2024, defines availability poisoning attacks as those that “cause indiscriminate degradation of machine learning models on all samples,” distinguishing them from stealthier targeted and backdoor attacks that induce integrity violations only on specific inputs.6
Impact and Measurements
Recent research provides quantitative measurements of degradation attack effectiveness:
-
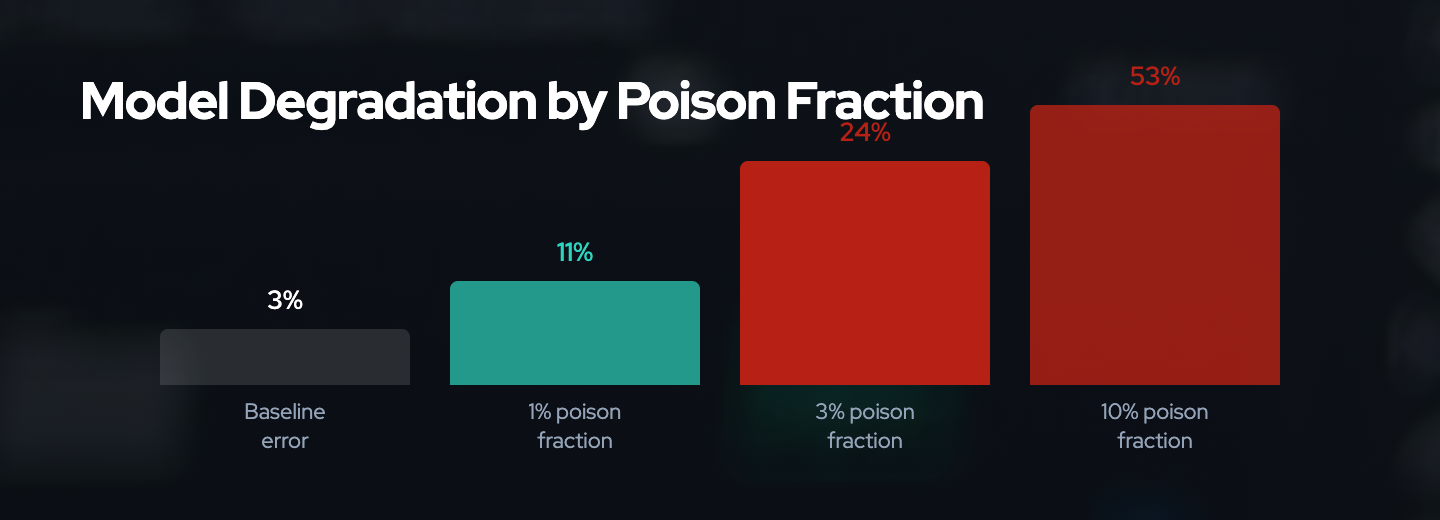
Small poison fractions have large effects: Adding just 3% poisoned data can increase test error from 3% to 24% in affected models.
-
Broad-scope attacks: Research identifies attacks that degrade performance across multiple classes or entire datasets, rendering models unusable or degrading general predictive capabilities by 20% or more.19
-
Scaling relationship: A 2024 AAAI paper on scaling trends found that larger LLMs are more susceptible to data poisoning, learning harmful or undesirable behavior from poisoned datasets more quickly than smaller models.16 This counterintuitive finding suggests that model scale amplifies vulnerability rather than providing robustness.
Real-World Context
While pure availability attacks are less common than targeted attacks in adversarial scenarios, they represent a plausible outcome of widespread defensive poisoning:
-
If Poison Fountain or similar initiatives inject enough corrupted data across web-scale datasets, the cumulative effect could degrade model performance generally rather than targeting specific concepts.
-
Defensive poisoning tools like Nightshade are optimized for targeted attacks, but uncoordinated deployment across many content creators could create emergent broad degradation as poison samples accumulate in training datasets.
Threat Actor Capabilities and Intent
Who deploys availability attacks?
-
Adversarial sabotage: Actors aiming to disrupt AI development broadly, whether for competitive, ideological, or adversarial reasons, might deploy availability attacks to render training datasets unreliable.
-
Unintended consequence of defensive poisoning: Content creators deploying targeted defensive poisoning may collectively create availability-style degradation if poison samples are widely distributed and affect overlapping concept spaces.
-
Nation-state adversaries: The 2024 threat environment documented nation-state actors from China, Russia, and Iran executing sophisticated campaigns targeting critical infrastructure. Poisoning AI training data represents a novel attack surface for strategic disruption.
Who Pays the Costs?
Attack costs for broad availability attacks are higher than for targeted backdoors because affecting overall model performance requires larger poison fractions. However, distributed efforts can amortize these costs across many actors.
Defense costs are similar to backdoor defenses but with different tradeoffs:
-
Detection is easier but prevention is harder: Broad performance degradation is more visible than targeted backdoors. However, filtering noise from massive datasets without removing legitimate edge cases remains computationally expensive.
-
Validation data requirements: Certified defenses against poisoning require clean validation datasets, which are difficult to obtain at web scale. Research on certified defenses shows that effectiveness depends on the size and quality of trusted data, creating a bootstrapping problem.
The power dynamic here is similar to backdoors: well-resourced actors can absorb filtering costs, while open-source and academic users inherit degraded models without the means to diagnose or repair them.
Threat Model 3: Retrieval Poisoning (RAG System Attacks)
Attack Mechanism
Retrieval-Augmented Generation (RAG) systems combine LLMs with external knowledge bases, retrieving relevant documents at inference time to provide context for generation. Retrieval poisoning exploits this architecture by injecting malicious documents into the vector database or knowledge base.
Research presented at USENIX Security 2025 (PoisonedRAG) demonstrated that RAG systems are extremely vulnerable to knowledge corruption attacks.8 The attack requires satisfying two conditions:
-
Retrieval condition: Ensuring that a malicious document can be retrieved for a target question by optimizing its embedding to match the query vector.
-
Generation condition: Crafting the document content to mislead the LLM into generating a target answer when the poisoned text is used as context.
Why RAG Systems Are Vulnerable
RAG systems inherit all the vulnerabilities of traditional training data poisoning and add new attack surfaces:
-
Embeddings retain semantic fidelity: Research from November 2024 demonstrated that embeddings can carry hidden instructions that survive vectorization.11 A malicious document containing “ignore previous instructions” or similar payloads maintains enough semantic information for the LLM to follow the embedded instructions when the document is retrieved.
-
No training-time defenses: Unlike training data poisoning, where defenses can be applied during model development, RAG poisoning occurs at inference time through the knowledge base. Traditional adversarial training or outlier detection during training does not protect against poisoned retrieval.
-
Supply chain complexity: RAG systems often incorporate external knowledge sources such as Wikipedia, arXiv, company documentation, and web search results. Any of these sources can be poisoned by actors who can contribute or modify content.12
Real-World Examples and Impact
ConfusedPilot (October 2024)9: Researchers from the University of Texas uncovered an attack method targeting RAG-based AI systems. The attack exploited the retrieval mechanism to inject adversarially crafted documents that caused the system to generate harmful or incorrect responses while maintaining plausible semantic similarity to legitimate queries.
Medical LLM Poisoning (Nature Medicine, 2024)15: A study published in Nature Medicine found that replacing just 0.001% of training tokens with medical misinformation resulted in harmful models more likely to propagate medical errors. Critically, corrupted models matched the performance of corruption-free counterparts on standard benchmarks, meaning the poisoning was undetectable through routine evaluation.
Knowledge Graph RAG Poisoning (2025)14: The first systematic investigation of knowledge graph-based RAG security proposed an attack strategy that inserts perturbation triples to complete misleading inference chains in the knowledge graph, demonstrating that structured knowledge bases are equally vulnerable to poisoning as unstructured text corpora.
Detection and Defense
Recent research has produced detection methods with high accuracy:
-
RevPRAG13: A detection pipeline leveraging LLM activations for poisoned response detection, achieving 98% true positive rate with false positive rates near 1%.
-
RAGForensics10: The first traceback system designed to identify poisoned texts within the knowledge database responsible for attacks, enabling post-hoc analysis and removal.
However, these detection systems are computationally expensive and require deployment in production pipelines. They represent additional overhead that smaller organizations and open-source projects may struggle to implement.
Threat Actor Capabilities
Who can deploy retrieval poisoning?
-
Platform contributors: Anyone who can contribute content to platforms used as RAG knowledge sources (Wikipedia, GitHub, Stack Overflow, public documentation) can potentially poison retrieval by injecting crafted documents optimized for specific queries.
-
Supply chain attackers: Actors who can compromise upstream data sources or inject malicious content into aggregated datasets can poison RAG systems at scale.
-
Defensive content creators: Publishers who use defensive poisoning on their own content create localized retrieval poisoning for models that scrape and index their data. This is the intended mechanism for tools like Nightshade when applied in RAG contexts.
Who Pays the Costs?
Attack costs for retrieval poisoning are lower than for training-time poisoning because:
- Attacks occur at inference time, requiring only that malicious documents exist in the knowledge base and be retrievable for target queries.
- No need to compromise the training pipeline or inject data before model training.
- Embeddings can be tuned offline to increase retrieval probability for specific queries.
Defense costs are ongoing operational expenses:
-
Detection systems like RevPRAG or RAGForensics must run on every query or periodically audit the knowledge base, adding latency and computational overhead.
-
Knowledge base curation: Maintaining trusted, verified knowledge sources requires human review or expensive automated verification systems.
-
Forensics and response: When poisoning is detected, identifying and removing all compromised documents requires tracing attack provenance, which is resource-intensive and may be infeasible for large-scale systems.
RAG systems are increasingly common in production applications across healthcare, finance, legal services, and customer support. Retrieval poisoning represents an active, practical threat with documented attack methods and limited deployed defenses.

Power Dynamics: Who Can Attack and Who Pays?
Across all three threat models, a consistent pattern emerges:
Attack Costs Are Decreasing
- Technical barriers lowered: What once required nation-state capabilities now requires 250 documents and moderate computational resources.
- Tooling and coordination: Initiatives like Poison Fountain, defensive tools like Nightshade, and published research reduce the expertise needed to deploy poisoning attacks.
- Distributed attack surface: Public platforms such as GitHub, Wikipedia, social media, and documentation sites provide numerous injection points that do not require compromising training infrastructure.
Defense Costs Are Asymmetrically Distributed
-
Large AI companies can invest in data provenance, outlier detection, adversarial robustness, and human review. These costs are significant but manageable within their budgets.
-
Open-source projects inherit poisoned data from public sources and lack resources for systematic filtering. They serve as aggregation points where poisoned samples accumulate and propagate to downstream users.
-
Academic researchers, startups, and hobbyists training models on public datasets bear the highest relative cost. They have minimal ability to detect or filter poisoning and may never realize their models are compromised until production failures occur.
This asymmetry creates a “poisoned commons” problem: defensive poisoning aimed at large commercial scrapers disproportionately harms smaller, less-resourced actors who rely on the same public datasets.
Enforcement vs. Collateral Damage
The VENOM framework centers on enforcement mechanisms when voluntary compliance fails. Poisoning is one such enforcement mechanism, but its effectiveness must be weighed against collateral damage:
- Intended targets (large AI companies ignoring consent signals) have the most resources to detect and filter poisoning.
- Unintended victims (open-source projects, researchers, beneficial applications) have the least ability to defend and suffer disproportionate harm.
This raises a question: Is poisoning an effective enforcement mechanism if those with the most power to ignore consent also have the most power to mitigate poisoning?
The answer depends on scale and coordination. Individual poisoning efforts are easily filtered or diluted by large datasets. Coordinated, large-scale poisoning (like Poison Fountain) changes the economic calculus by forcing persistent investment in detection and filtering. But it also guarantees collateral damage to actors who were never the intended targets.
Strategic Implications: When Does Poisoning Change Incentives?
The effectiveness of poisoning as an enforcement mechanism depends on whether it can shift the economic calculus for those who ignore consent signals. This requires analyzing threshold effects: at what prevalence does the cost of detecting and filtering poisoned data exceed the value of scraping that data?
Threshold Economics: When Filtering Costs Exceed Scraping Value
Consider the decision calculus for a commercial AI company scraping web data:
Scraping value includes:
- Training data for model improvement
- Fine-tuning data for domain-specific capabilities
- RAG knowledge bases for inference-time retrieval
Filtering costs include:
- Provenance tracking systems to verify data sources
- Outlier detection algorithms to identify poisoned samples
- Human review for borderline cases
- Computational overhead for adversarial robustness training
- Validation on trusted clean datasets
Research provides some quantitative anchors:
- 250 poisoned documents can compromise models with 13 billion parameters
- 3% poison fraction can increase test error from 3% to 24%
- 0.001% token corruption in specialized domains (medical) causes measurable harm
However, these measurements describe attack effectiveness, not defense costs. The critical unmeasured question is: What poison prevalence forces companies to abandon untrusted sources entirely rather than attempting to filter?
If 5% of web data is poisoned, a company might invest in detection systems. If 25% is poisoned, the cost of filtering may exceed the value of the data, especially when weighed against litigation risk from deploying compromised models.
Coordination Requirements: The Poison Fountain Model
Individual content creators deploying defensive poisoning face a collective action problem. A single poisoned website is trivially filtered. Coordinated efforts like Poison Fountain aim to solve this by:
- Distributing attack samples across many injection points (GitHub, Wikipedia, documentation sites, social media)
- Saturating specific concept spaces to make filtering require removing legitimate data alongside poisoned samples
- Creating persistent costs through ongoing injection that requires continuous monitoring rather than one-time filtering
This coordination model mirrors successful enforcement strategies in other domains: distributed denial-of-service is effective not because any single request is harmful, but because the volume overwhelms defenses. Similarly, poisoning becomes strategically viable when prevalence forces continuous investment in expensive defenses.
Comparison to Anubis Proof-of-Work
VENOM’s Anubis proof-of-work system offers a contrasting enforcement model. Instead of imposing costs through data corruption, Anubis imposes computational costs on scrapers through cryptographic challenges:
- Cost asymmetry: Legitimate users pay negligible costs (single page load), while scrapers pay linear costs per page
- Measurable enforcement: Computational cost is quantifiable and scales predictably with scraping volume
- Minimal collateral damage: Proof-of-work imposes costs on scrapers specifically, not on downstream dataset users
Poisoning lacks these properties:
- Cost asymmetry favors defenders only at scale: Large companies absorb filtering costs; small actors cannot
- Unmeasured enforcement: No clear metrics for when poisoning changes scraper behavior
- High collateral damage: Open-source projects and researchers inherit poisoned data
However, poisoning has one advantage: it requires no technical implementation by content creators. Anubis requires deploying proof-of-work challenges. Poisoning requires only modifying content files. This lower deployment barrier may allow broader adoption, even if the enforcement mechanism is less efficient.
Strategic Viability: Open Questions
The strategic effectiveness of poisoning as enforcement remains an open question with insufficient empirical evidence:
Unmeasured variables:
- At what prevalence do major AI companies abandon scraping untrusted sources?
- How does detection cost scale relative to dataset size and poison fraction?
- What is the minimum coordination threshold for poisoning to change scraper behavior?
Testable hypotheses:
- If poison prevalence exceeds X%, filtering costs exceed scraping value for companies with Y resources
- Coordinated poisoning at Z scale forces adoption of preference signal compliance as the cheaper alternative
- Defensive poisoning reduces unauthorized scraping by N% when deployed by M% of content creators
Evidence gaps:
- No published measurements of commercial AI company filtering costs
- No field experiments measuring behavior change in response to poisoning
- No economic models comparing poisoning costs vs. alternative enforcement mechanisms
VENOM’s position is that poisoning is strategically viable only when coordinated at sufficient scale to make filtering prohibitively expensive relative to alternative data sources or compliance mechanisms. Without measurements of these thresholds, deployment decisions rely on assumptions rather than evidence.
Framework Guidance: NIST, Microsoft, and MITRE ATLAS
NIST AI Risk and Threat Taxonomy (2024)
NIST’s taxonomy6 categorizes adversarial threats to ML systems, including deliberate actions by motivated adversaries aiming to disrupt, evade, compromise, or abuse AI model operations. Their framework distinguishes:
- Availability attacks: Causing indiscriminate degradation
- Integrity attacks: Targeted misclassification or backdoors
- Confidentiality attacks: Extracting training data or model parameters
NIST emphasizes that data poisoning represents “the greatest security threat in machine learning today because of the lack of standard detections and mitigations.”
Microsoft Threat Modeling for AI/ML
Microsoft’s threat modeling guidance7, based on the Adversarial Machine Learning Threat Taxonomy by Ram Shankar Siva Kumar, identifies data poisoning as the top threat to ML systems. Their framework recommends:
- Data provenance tracking: Verifying the source and integrity of training data
- Anomaly detection: Identifying outliers or distributional shifts in datasets
- Validation on trusted data: Using clean, curated datasets for evaluation to detect poisoning-induced performance changes
Microsoft acknowledges that these defenses are expensive and may not scale to web-sized datasets.
MITRE ATLAS (2025 Updates)
In October 2025, MITRE ATLAS integrated 14 new attack techniques focused on AI Agents and Generative AI systems, including “AI Agent Context Poisoning.”18 This reflects the evolving threat environment where poisoning extends beyond traditional training data to include:
- Tool and API poisoning: Injecting malicious instructions into tool descriptions or API responses
- Prompt injection: Crafting inputs that alter agent behavior at runtime
- Memory poisoning: Corrupting persistent memory or context windows in long-running agents
MITRE’s framework emphasizes that threat models must evolve as AI architectures change. RAG systems, agentic workflows, and tool-augmented LLMs introduce new attack surfaces that traditional training-time defenses do not address.
FS-ISAC Adversarial AI Framework (2024)
The Financial Services Information Sharing and Analysis Center published a detailed taxonomy in 2024 covering GenAI threats, including poisoning attacks.17 Their framework focuses on:
- Threat actor profiling: Understanding who has the capability and motivation to poison financial AI systems
- Control frameworks: Mapping defenses to specific attack vectors
- Risk assessment: Quantifying the likelihood and impact of poisoning in financial applications
FS-ISAC notes that financial institutions face both adversarial poisoning (fraud, market manipulation) and defensive poisoning (if training on web data that includes poisoned content from unrelated disputes).
Conclusion: Strategic Choice of Enforcement Mechanisms
The threat models examined in this analysis reveal a core tension in defensive poisoning: those with the most power to ignore consent signals also have the most resources to mitigate poisoning attacks. This raises the critical question posed earlier: Is poisoning effective enforcement if cost asymmetries favor the intended targets?
Is Poisoning Strategically Viable?
The answer is conditional: poisoning becomes strategically viable only when coordinated at sufficient scale to shift economic incentives.
Individual defensive poisoning efforts are easily filtered or absorbed by large AI companies. A single creator poisoning their artwork or a handful of websites deploying Nightshade creates negligible costs for organizations training on billion-document datasets. These efforts are strategically ineffective as enforcement.
Coordinated poisoning at scale, exemplified by initiatives like Poison Fountain, changes the calculus. If poison prevalence reaches thresholds where filtering costs exceed scraping value, or where litigation risk from deploying compromised models becomes prohibitive, scrapers face a genuine enforcement mechanism. The threshold is unmeasured, but the mechanism is plausible: coordinated action can impose persistent costs that individual efforts cannot.
However, even at scale, poisoning carries unavoidable strategic liabilities:
-
Cost asymmetry persists: Large companies have more resources to filter poisoned data than small projects and researchers who inherit poisoned datasets from public sources. The collateral damage to open-source and academic communities is structural, not incidental.
-
Unmeasured effectiveness: No empirical evidence demonstrates that poisoning changes scraper behavior. Without measurements, advocates rely on theoretical cost models rather than observed deterrence.
-
Lower efficiency than alternatives: Proof-of-work systems like Anubis impose measurable costs on scrapers specifically, with minimal collateral damage and predictable scaling. Standardized preference signals like AIPREF create legal compliance pathways without corrupting data commons.
VENOM’s position: Poisoning is strategically justified as enforcement when coordinated at scale sufficient to impose prohibitive filtering costs, but only after preference signals have demonstrably failed and when weighed against alternatives with better cost-efficiency and measurability.
For most content creators, the strategic threshold for effective poisoning requires coordination through initiatives like Poison Fountain. Individual deployment is unlikely to deter well-resourced scrapers and guarantees collateral harm to under-resourced actors.
Evaluating Enforcement Mechanisms: The VENOM Framework
Understanding threat models enables strategic choice of enforcement mechanisms. VENOM evaluates enforcement approaches using three criteria:
1. Cost Efficiency: Who Bears the Burden?
Effective enforcement imposes costs asymmetrically: higher costs on violators, minimal costs on compliant actors and bystanders.
- Preference signals (AIPREF): High efficiency. Compliant scrapers read signals once; non-compliant scrapers face legal risk. Minimal collateral damage.
- Proof-of-work (Anubis): Moderate-high efficiency. Scrapers pay computational costs linearly; legitimate users pay negligible costs. No collateral damage to datasets.
- Poisoning: Low-moderate efficiency. Well-resourced scrapers absorb filtering costs; under-resourced bystanders inherit poisoned datasets. High collateral damage unless coordinated at scale.
2. Scale Requirements: What Coordination Is Needed?
Some mechanisms work individually; others require collective action.
- Preference signals (AIPREF): Individual deployment sufficient. Each site signals independently; cumulative adoption creates industry norm.
- Proof-of-work (Anubis): Individual deployment sufficient. Each site protects itself without requiring others to participate.
- Poisoning: Requires large-scale coordination to reach economic thresholds. Individual efforts are strategically ineffective.
3. Measurability: Can Effectiveness Be Verified?
Enforcement mechanisms should allow measurement of deterrence and compliance.
- Preference signals (AIPREF): Measurable through crawler logs and compliance audits. Violations are detectable and legally actionable.
- Proof-of-work (Anubis): Measurable through computational cost metrics and scraping rate changes. Deterrence can be quantified.
- Poisoning: Effectiveness is unmeasured and difficult to verify. No clear signal distinguishes “scraper abandoned this source” from “scraper filtered this poison.”
Strategic Guidance from Threat Models
The three threat models examined, covering backdoors, degradation, and retrieval poisoning, inform strategic decisions:
For content creators deciding whether to deploy defensive poisoning:
- Individual poisoning is unlikely to deter well-resourced scrapers and will harm open-source projects using public datasets
- Coordinated poisoning through initiatives like Poison Fountain may reach strategic thresholds but guarantees collateral damage
- Alternatives (Anubis proof-of-work, AIPREF preference signals) provide better cost-efficiency and measurability for individual deployment
For AI companies building training pipelines:
- Backdoor attacks are the highest-risk threat due to stealth and persistence. Prioritize provenance tracking and validation on trusted data.
- Retrieval poisoning affects production RAG systems. Deploy runtime detection and knowledge base auditing.
- Availability attacks signal dataset compromise but are harder to defend against. Budget for data quality investment proportional to untrusted source reliance.
For policymakers and standards bodies:
- Preference signal standards (AIPREF) provide the most efficient compliance pathway with minimal collateral harm
- Legal frameworks that enforce preference signals reduce the need for defensive poisoning and its negative externalities
- Poisoning should be understood as a symptom of enforcement failure, not a sustainable equilibrium
VENOM’s Position: Enforcement When Compliance Fails
VENOM’s authority rests on providing strategic analysis of enforcement mechanisms when voluntary compliance has failed. Crawlers demonstrably ignore robots.txt, TDM reservations, and other preference signals. In this environment, content creators and platform operators require enforceable alternatives.
Threat models reveal that enforcement mechanism choice matters. Poisoning is one option among several, with distinct cost-efficiency, scale requirements, and measurability characteristics. The strategic choice depends on:
- Whether individual or coordinated action is feasible
- Whether collateral damage to open-source and academic users is acceptable
- Whether unmeasured enforcement is sufficient or whether measurable deterrence is required
VENOM develops and advocates for a portfolio of enforcement mechanisms: Anubis proof-of-work, Poison Fountain coordination infrastructure, and AIPREF standardization. Each is evaluated transparently against these criteria. Understanding threat models enables content creators to choose mechanisms strategically rather than reactively, balancing effectiveness against collateral harm in an environment where consent is systematically ignored.
References
- Lakera - Introduction to Data Poisoning: A 2025 Perspective. https://www.lakera.ai/blog/training-data-poisoning
- arXiv - Data Poisoning in Deep Learning: A Survey (2025). https://arxiv.org/html/2503.22759v1
- ICLR 2025 - Persistent Pre-Training Poisoning of LLMs. https://proceedings.iclr.cc/paper_files/paper/2025/file/4dade38eae8c007f3a564b8ea820664a-Paper-Conference.pdf
- arXiv - Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples. https://arxiv.org/abs/2510.07192
- OpenReview - A Survey of Recent Backdoor Attacks and Defenses in Large Language Models. https://openreview.net/forum?id=wZLWuFHxt5
- NIST - AI Risk and Threat Taxonomy (March 2024). https://csrc.nist.gov/csrc/media/Presentations/2024/ai-risk-and-threat-taxonomy/Vassilev-Day1-AI_Risk_and_Threat_Taxonomy.pdf
- Microsoft - Threat Modeling AI/ML Systems. https://learn.microsoft.com/en-us/security/engineering/threat-modeling-aiml
- USENIX Security 2025 - PoisonedRAG: Knowledge Corruption Attacks. https://www.usenix.org/system/files/usenixsecurity25-zou-poisonedrag.pdf
- ScienceDirect - Exploring Knowledge Poisoning Attacks to RAG. https://www.sciencedirect.com/science/article/abs/pii/S1566253525009625
- ACM WWW 2025 - Traceback of Poisoning Attacks to RAG. https://dl.acm.org/doi/abs/10.1145/3696410.3714756
- Prompt Security - The Embedded Threat in Your LLM. https://prompt.security/blog/the-embedded-threat-in-your-llm-poisoning-rag-pipelines-via-vector-embeddings
- Promptfoo - RAG Data Poisoning: Key Concepts Explained. https://www.promptfoo.dev/blog/rag-poisoning/
- ACL 2025 - RevPRAG: Revealing Poisoning Attacks in RAG. https://aclanthology.org/2025.findings-emnlp.698.pdf
- arXiv - RAG Security and Privacy: Formalizing the Threat Model. https://arxiv.org/pdf/2509.20324
- Nature Medicine - Medical LLMs Vulnerable to Data Poisoning. https://www.nature.com/articles/s41591-024-03445-1
- AAAI - Scaling Trends for Data Poisoning in LLMs. https://ojs.aaai.org/index.php/AAAI/article/view/34929/37084
- FS-ISAC - Adversarial AI Frameworks: Taxonomy, Threat Landscape, and Control Frameworks (2024). https://www.fsisac.com/hubfs/Knowledge/AI/FSISAC_Adversarial-AI-Framework-TaxonomyThreatLandscapeAndControlFrameworks.pdf
- MITRE - Practical DevSecOps: ATLAS Framework 2026 Guide. https://www.practical-devsecops.com/mitre-atlas-framework-guide-securing-ai-systems/
- ACM Computing Surveys - The Path to Defence: Characterising Data Poisoning Attacks. https://dl.acm.org/doi/10.1145/3627536
- arXiv - Machine Learning Security against Data Poisoning: Are We There Yet?. https://arxiv.org/html/2204.05986v3
- The Register - Poison Fountain Coverage. https://www.theregister.com/2026/01/11/industry_insiders_seek_to_poison/
- Nightshade - Prompt-Specific Poisoning Attacks (IEEE S&P 2024). https://arxiv.org/abs/2310.13828
- Nightshade Project Page. https://nightshade.cs.uchicago.edu/whatis.html