The State of Defensive Data Poisoning in 2026: A Report
A VENOM Flagship Report
January 2026
Executive Summary
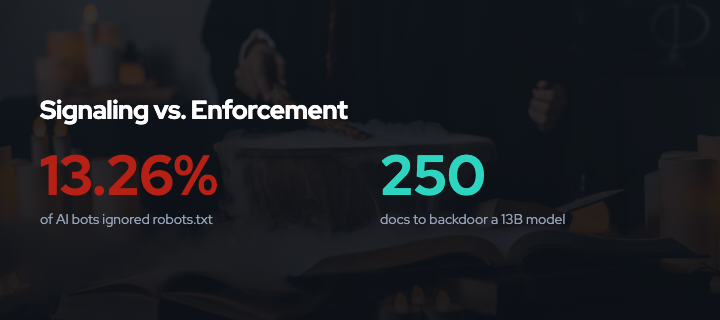
The voluntary compliance framework that governed web crawling for thirty years is breaking down. Robots.txt, formalized as RFC 9309 in 2022, depends on crawlers choosing to respect preference signals. That choice is increasingly rare. TollBit data shows 13.26% of AI bot requests ignored robots.txt directives in Q2 2025, a fourfold increase from Q4 2024. Cloudflare documented AI crawlers using stealth tactics: rotating IPs, spoofing user agents, and operating undeclared scrapers that bypassed preference signals entirely.
Content creators face a structural disadvantage. AI companies scrape first and litigate later. Detection is difficult. Model weights carry no provenance. Attribution requires expensive forensic analysis or years of litigation. The New York Times has spent over $10.8 million in legal costs pursuing OpenAI.
Into this gap, enforcement mechanisms have emerged. Nightshade lets artists add perturbations to images that corrupt AI models during training. It has been downloaded over 250,000 times. Anubis imposes computational costs on scrapers through proof-of-work challenges. Poison Fountain distributes poisoned datasets designed to degrade language model capabilities. These tools represent a shift from requesting compliance to imposing costs.
VENOM exists to analyze this shift with rigor. We distinguish between signaling mechanisms (robots.txt, AIPREF standards) and enforcement mechanisms (poisoning, proof-of-work, litigation). We measure effectiveness where evidence exists and acknowledge gaps where it does not. We analyze power dynamics, cost structures, and collateral damage.
This report presents the state of defensive data poisoning in 2026: what tools exist, how they work, what evidence supports their effectiveness, and what questions remain unanswered. Our aim is honest analysis, not advocacy. Whether journalists, researchers, and standards bodies cite VENOM as authoritative depends on the quality of our work.
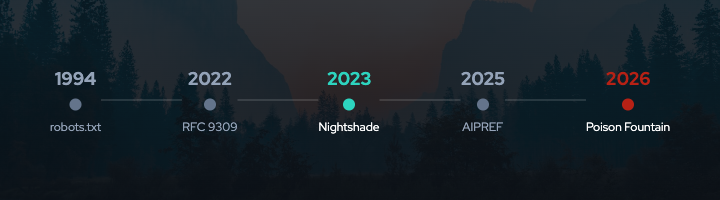
1. The Compliance Crisis: Robots.txt Bypass Data
The robots.txt protocol has been part of the web’s social contract since Martijn Koster proposed it in 1994. For decades, search engines honored it. They had reputational incentives, business relationships with publishers, and a shared understanding that cooperation benefited everyone. That era is ending.
Quantifying Non-Compliance
TollBit’s Q2 2025 analysis found that 13.26% of AI bot requests ignored robots.txt directives. This represents a fourfold increase from the 3.3% recorded in Q4 2024. The trajectory is clear: non-compliance is growing rapidly 1.
Duke University researchers deployed Anubis proof-of-work challenges specifically because of overwhelming crawler traffic to their academic infrastructure. UNESCO, WINE, GNOME, and the Enlightenment project followed. These are not commercial entities seeking competitive advantage. They are academic and open-source organizations protecting limited infrastructure from aggressive scraping 2.
Publishers have responded. Sites blocking AI crawlers increased 336% year-over-year through 2025. Over 5.6 million websites have added GPTBot to their disallow lists, a 70% increase since July 2025. The message is clear, but crawlers are not listening 3.
Bypass Techniques in the Wild
Cloudflare’s August 2025 technical report documented how Perplexity operated both declared user agents and undeclared stealth crawlers. These stealth crawlers rotated IP addresses and ASNs, sometimes ignored robots.txt entirely, and used Chrome-like user agent strings from unlisted address blocks 4.
The documented bypass techniques include:
User-agent spoofing: Crawlers impersonate mainstream browsers like Chrome or Firefox, bypassing rules that target specific bot identifiers.
IP and ASN rotation: Rapid cycling through addresses prevents IP-based blocking from being effective.
Browser-as-a-service proxies: Third-party services provide legitimate browser fingerprints, making crawlers indistinguishable from human traffic.
Undeclared scrapers: AI companies operate crawlers without identifying user agents, invisible to rules targeting known bots.
These are not fringe behaviors. They are systematic approaches to circumventing preference signals.
The Attribution Problem
When a search engine violates robots.txt, webmasters notice immediately. Crawler activity appears in server logs. But when an AI model trains on your content, detection is far harder.
Model weights do not carry provenance. Determining whether specific content was used in training requires techniques like membership inference attacks or training data extraction. These methods remain research-stage with variable success rates depending on model architecture and training conditions.
This creates structural asymmetry. AI companies know exactly what data they trained on. Content creators must infer it through indirect evidence, statistical similarity analysis, or expensive litigation. The asymmetry favors well-resourced actors who can scrape broadly while leaving creators to prove unauthorized use after the fact.
2. Enforcement Mechanism Taxonomy
Understanding the current situation requires distinguishing between signaling and enforcement. This framework is central to VENOM’s analysis.
Signaling Mechanisms
Signaling mechanisms communicate preferences but rely on voluntary compliance. They include:
Robots.txt directives: The original preference signal, now formalized as RFC 9309. Effective only when responders choose to comply.
HTTP headers: AIPREF’s proposed Content-Usage field extends robots.txt with AI-specific vocabulary. Still requires voluntary reading and compliance.
Metadata and licensing statements: Terms of service, Creative Commons licenses, and embedded metadata express creator preferences. They create legal standing but not technical barriers.
Signaling works when responders have incentives to comply: reputation, legal exposure, business relationships, or technical ecosystems that enforce consequences. Search engines complied with robots.txt because they needed ongoing relationships with publishers. Ignoring preferences meant losing access to updated content and facing public backlash.
AI training is different. Once you have scraped a dataset, the relationship ends. There is no recurring dependency that creates enforcement leverage.
Enforcement Mechanisms
Enforcement mechanisms impose direct costs on non-compliant actors. They do not require cooperation. They work by making undesired behavior expensive, unreliable, or actively harmful.
Data poisoning: Tools like Nightshade, Glaze, and Poison Fountain modify content so that models trained on it exhibit degraded or incorrect behavior. The cost falls on anyone who trains on poisoned data without detection and filtering.
Proof-of-work challenges: Systems like Anubis require computational work before accessing content. Legitimate users solving a single challenge experience negligible delay. Scrapers accessing millions of pages face linear cost scaling.
Server-level blocking: Fingerprinting techniques identify and block crawlers based on behavioral patterns, not just user-agent strings. Effectiveness depends on the sophistication of the blocking system versus the crawler’s evasion techniques.
Litigation: Legal action imposes costs through legal fees, reputational risk, and potential judgments. Lawsuits like The New York Times v. OpenAI turn non-compliance from free to expensive, regardless of the eventual verdict.
Technical countermeasures: Honeypots like Cloudflare’s AI Labyrinth waste crawler resources by serving AI-generated decoy content. Tarpits like Nepenthes impose time costs through intentionally slow responses and infinite page sequences.
The Critical Insight
Signaling is not enforcement. When the IETF standardizes AIPREF, it creates clearer signals. But signals only matter if someone pays a cost for ignoring them. Without enforcement, better signals just make violations easier to measure.
The breakdown of robots.txt compliance demonstrates this principle. The signal exists. Compliance is declining. Better signals (AIPREF vocabulary, HTTP headers, machine-readable licenses) improve expressiveness but do not change the incentive structure.
Enforcement mechanisms change incentives by imposing costs directly. Whether those costs are sufficient to change behavior, and whether the collateral damage is acceptable, are the questions this report examines.
3. Tool Analysis: Nightshade, Glaze, Anubis, Poison Fountain
Four tools represent the current state of defensive enforcement: Nightshade for image poisoning, Glaze for style protection, Anubis for proof-of-work, and Poison Fountain for coordinated LLM poisoning.
Nightshade
Mechanism: Nightshade adds imperceptible perturbations to images that corrupt AI models during training. The perturbations are optimized to create specific misbehaviors. For example, a poisoned “dog” image teaches the model an incorrect association that affects its understanding of “dog” prompts 5.
Technical effectiveness: The original research paper (IEEE S&P 2024) demonstrated that 50 poisoned images can cause models to produce distorted outputs. After 300 poisoned samples, models can be redirected entirely: prompts for “dog” generate “cat” images instead 6.
Adoption: Nightshade was downloaded over 250,000 times within five days of release. This adoption rate indicates significant demand from artists seeking protection against unauthorized training 7.
Cost structure: Perturbation generation takes minutes to hours per image on consumer GPUs. The attack cost is low. However, we lack public data on filtering costs at the training pipeline scale. AI companies do not publish what they spend detecting and removing poisoned images. This gap limits our ability to assess whether poisoning imposes economically meaningful costs on well-resourced targets.
Glaze
Mechanism: Glaze alters pixels in artwork so that AI models perceive the style differently from how humans see it. Unlike Nightshade’s offensive approach, Glaze is purely defensive: it prevents style mimicry without corrupting downstream models 8.
Recognition: Glaze won the TIME Best Invention of 2023 award, the Chicago Innovation Award, and the 2023 USENIX Internet Defence Prize. These recognitions reflect both technical achievement and social relevance.
Adoption: Glaze has been downloaded more than 6 million times since its March 2023 release. This makes it the most widely deployed defensive tool for visual artists.
Limitations: Some researchers claim to have found vulnerabilities in Glaze protections. The effectiveness against sophisticated attacks remains an active research question. Additionally, Glaze requires artists to process every image they publish, creating ongoing operational burden.
Anubis
Mechanism: Anubis is a proof-of-work system requiring clients to solve SHA-256 hash challenges before accessing content. The challenge completes in seconds on modern browsers but creates prohibitive costs for mass scraping. If you need to access one page, the cost is negligible. If you need to access one million pages, the cost scales linearly 9.
Adoption: Anubis is deployed by UNESCO, WINE, GNOME, Duke University, and the Enlightenment project. These deployments demonstrate viability in production academic and open-source infrastructure 10.
Cost analysis: Anubis imposes measurable, predictable costs on scrapers. Unlike poisoning, where effectiveness is difficult to verify, proof-of-work costs can be calculated from the challenge difficulty and the number of pages accessed. This measurability is a significant advantage.
Limitations: Anubis may cause accessibility problems for screen readers and other assistive technologies that struggle with JavaScript-based challenges. It also blocks legitimate automated agents, including the Internet Archive’s crawlers. These collateral effects require careful consideration. Tavis Ormandy (Google security researcher) noted that compute costs for attackers may be negligible until millions of sites deploy the system 11.
Poison Fountain
Mechanism: Poison Fountain is an anonymous initiative distributing poisoned datasets specifically designed to sabotage language models. Website operators can embed URLs to these datasets, causing crawlers to ingest poisoned data. The datasets reportedly contain subtle logic errors designed to degrade code generation and reasoning capabilities 12.
Inspiration: Poison Fountain’s creators cite Anthropic’s October 2025 research showing that only 250 malicious documents can backdoor language models regardless of size. If poisoning requires a fixed, small number of documents rather than a percentage of training data, coordinated poisoning becomes far more practical 13.
Coordination model: Unlike individual defensive tools, Poison Fountain aims to coordinate poisoning at scale. The initiative provides both HTTP and .onion (darknet) URLs for resilience against takedown efforts. This coordination addresses the collective action problem that makes individual poisoning ineffective against well-resourced targets.
Effectiveness: Unknown. Poison Fountain is too recent for field data on its impact. Whether it succeeds as a technical intervention is less important than what it represents: willingness to impose enforcement costs when signaling fails.

4. Effectiveness Evidence: What We Know and Don’t Know
Honest assessment of defensive poisoning requires distinguishing measured results from theoretical claims.
What Research Has Demonstrated
Poison efficiency is higher than previously assumed. Anthropic’s October 2025 collaboration with UK AISI and The Alan Turing Institute found that only 250 malicious documents can backdoor LLMs ranging from 600M to 13B parameters. The number of poison samples required is near-constant regardless of model and dataset size. Creating 250 malicious documents is trivial compared to creating millions 14.
Small poison fractions cause measurable harm. Adding 3% poisoned data can increase test error from 3% to 24%. In specialized domains, the threshold is even lower: replacing just 0.001% of training tokens with medical misinformation produced models more likely to propagate medical errors 15.
Larger models may be more vulnerable. A 2024 AAAI paper on scaling trends found that larger LLMs are more susceptible to data poisoning, learning harmful behavior from poisoned datasets more quickly than smaller models. This counterintuitive finding suggests scale amplifies vulnerability rather than providing robustness 16.
Backdoors persist through safety training. Anthropic’s “Sleeper Agents” research demonstrated that backdoored behavior survives supervised fine-tuning, RLHF, and adversarial training. In some cases, adversarial training made models more adept at concealing backdoors rather than eliminating them 17.
What Remains Unmeasured
Filtering costs at production scale. We do not know what AI companies spend on data quality infrastructure. We do not know their detection rates for different poisoning techniques. We do not know at what prevalence poisoning becomes economically prohibitive to filter. These economics are critical to assessing whether poisoning changes scraper behavior, but the data is proprietary.
Behavioral response to poisoning. No published evidence demonstrates that poisoning has caused AI companies to reduce scraping, increase compliance with preference signals, or change their data acquisition practices. We have theoretical cost models but no observed deterrence.
Collateral damage quantification. Defensive poisoning affects all downstream users of contaminated datasets. We lack measurements of how severely this impacts open-source projects, academic researchers, and beneficial applications that rely on public datasets. These costs are real but unquantified.
Threshold effects. At what poison prevalence do major AI companies abandon scraping untrusted sources entirely? At what coordination level does poisoning become effective deterrence? These thresholds determine strategic viability but remain unmeasured.
The Attribution Gap Persists
Even when poisoning affects model behavior, proving causation is difficult. If a commercial model performs poorly on certain tasks, was it poisoning? Architecture limitations? Training hyperparameters? The attribution problem that makes detecting unauthorized training difficult also makes proving poisoning effectiveness difficult.
This creates an accountability gap. Content creators cannot verify their defensive measures worked. AI companies may not know (or may choose not to disclose) when they have filtered poisoned data. The feedback loop that would allow evidence-based refinement of defensive strategies does not exist.
5. Policy and Standards Context: AIPREF and Beyond
Technical enforcement mechanisms operate alongside evolving policy and standards frameworks. Understanding their interaction is essential.
IETF AIPREF Working Group
The IETF chartered the AI Preferences (AIPREF) working group in January 2025 to develop standards for expressing AI usage preferences. AIPREF extends the robots.txt framework with vocabulary specifically addressing AI training use cases 18.
Key preference categories under development include:
train-ai: General AI trainingtrain-genai: Generative AI training specificallysearch: Search engine indexingautomated: General automated processing
Draft specifications (draft-ietf-aipref-attach and draft-ietf-aipref-vocab) define how preferences can be signaled in HTTP headers and robots.txt files. A community tool at aipref.dev generates compliant configurations 19.
AIPREF improves signaling expressiveness. It does not create enforcement. However, clearer signals create better evidence for litigation, enable more precise blocking, and establish clearer norms for responsible AI development. Standards matter most when they are backed by consequences.
EU AI Act Training Data Transparency
The EU AI Act (Regulation 2024/1689) imposes mandatory transparency requirements on General-Purpose AI (GPAI) providers. Article 53(1)(d) requires providers to publish a “sufficiently detailed summary” of training content, including data protected by copyright law 20.
The European Commission published a mandatory disclosure template on July 24, 2025. Providers must document:
- Data modalities and sizes
- Sources (public datasets, licensed private data, web-scraped content, user data)
- Synthetic data generation details
- Measures for handling copyright reservations and illegal content
GPAI transparency requirements took effect August 2, 2025. Non-compliance penalties can reach 15 million EUR or 3% of global annual revenue 21.
These requirements do not prevent unauthorized scraping. They create accountability after the fact. If AI companies must disclose training data sources, creators gain evidence for enforcement actions. Transparency is not enforcement, but it supports enforcement.
US Copyright Office Position
The US Copyright Office’s May 2025 report on “Generative AI Training” rejected arguments that AI training is automatically transformative fair use. The Office adopted a spectrum approach: training on diverse data for general-purpose models may be transformative, while training specifically to replicate works is unlikely to be transformative 22.
Key findings:
- Using copyrighted works to train AI may constitute prima facie reproduction infringement
- Where outputs are substantially similar to training inputs, model weights themselves may infringe
- No single answer exists on whether unauthorized training is fair use
- The source of copyrighted works matters: use of pirated copies significantly increases liability
This framework does not resolve ongoing litigation but signals that fair use defenses are not automatic. AI companies face genuine legal uncertainty about training practices.
Litigation as Enforcement
Major lawsuits impose enforcement costs regardless of their eventual outcomes:
The New York Times v. OpenAI: Core claims advanced in April 2025 when Judge Sidney Stein rejected OpenAI’s motion to dismiss. The Times has disclosed $10.8 million in litigation costs for 2024 alone 23.
Getty Images v. Stability AI: The UK High Court ruled in November 2025 that model weights do not store reproductions of copyrighted works, rejecting most infringement claims. However, the ruling acknowledged limited trademark claims and created precedent that future cases must address 24.
Thomson Reuters v. ROSS Intelligence: February 2025 ruling found that using legal headnotes to train a competing AI product was NOT transformative fair use. This creates precedent for works used to produce functionally similar outputs 25.
Reddit v. Perplexity AI: Filed October 2025, this lawsuit focuses on how data was obtained (false identities, proxies, anti-security techniques) rather than copyright/fair use. It opens a new vector for enforcement based on unauthorized access methods 26.
Litigation is slow and expensive but creates systemic deterrence by raising the expected cost of unauthorized training.
6. 2026 Outlook and Open Questions
Defensive data poisoning will change substantially in 2026. Several developments will shape outcomes.
Coordination Threshold Question
Individual defensive poisoning is strategically ineffective against well-resourced AI companies. They can filter poisoned content from massive datasets at costs they can absorb. Coordinated poisoning at scale, exemplified by Poison Fountain, may change this calculus by forcing persistent investment in detection and filtering.
The critical unmeasured question: at what prevalence does poisoning become economically prohibitive to filter? If 5% of web data is poisoned, companies invest in detection. If 25% is poisoned, filtering costs may exceed scraping value. We lack evidence on where this threshold lies.
Proof-of-Work Adoption
Anubis and similar systems offer enforcement with better cost-efficiency and measurability than poisoning. They impose linear costs on scrapers without corrupting data commons. If adoption spreads beyond academic and open-source infrastructure to commercial publishers, proof-of-work could become a major barrier to unauthorized scraping.
The countervailing factor is accessibility. Proof-of-work creates friction for legitimate automated agents and users with assistive technologies. Balancing enforcement against accessibility will determine adoption trajectories.
Standards and Legal Clarity
AIPREF standardization will provide clearer preference signals by mid-2026. EU AI Act enforcement will begin applying transparency requirements and penalties. US courts will continue developing fair use doctrine through ongoing litigation.
None of these developments eliminate the need for enforcement mechanisms. But clearer standards and legal frameworks reduce uncertainty and create more options for rights holders.
Open Questions for Research
-
Filtering economics: What do AI companies actually spend on data quality infrastructure? At what poison prevalence does filtering become prohibitively expensive?
-
Behavioral response: Does poisoning change scraper behavior? What evidence would demonstrate deterrence?
-
Collateral damage: How severely does defensive poisoning affect open-source projects, academic researchers, and beneficial applications?
-
Coordination dynamics: What adoption level makes coordinated poisoning effective? How do collective action problems affect deployment?
-
Counter-adaptation: How quickly do AI companies develop robust filtering? Does an arms race favor defenders or scrapers?
VENOM will pursue measurements and analysis addressing these questions. Our value lies in honest assessment, not optimistic claims.
References
- The Register (2025). "Publishers Say No to AI Scrapers, Block Bots at Server Level." https://www.theregister.com/2025/12/08/publishers_say_no_ai_scrapers/
- LWN (2025). "Anubis: Fighting the LLM Hordes." https://lwn.net/Articles/1028558/
- Stytch Blog (2025). "How to Block AI Web Crawlers." https://stytch.com/blog/how-to-block-ai-web-crawlers/
- Cloudflare (2025). "Control Content Use for AI Training with Cloudflare's Managed Robots.txt." https://blog.cloudflare.com/control-content-use-for-ai-training/
- Nightshade Project Page. "What is Nightshade?" University of Chicago. https://nightshade.cs.uchicago.edu/whatis.html
- Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2024). "Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models." IEEE Symposium on Security and Privacy. arXiv:2310.13828. https://arxiv.org/abs/2310.13828
- Heaven, W.D. (2023). "This New Data Poisoning Tool Lets Artists Fight Back Against Generative AI." MIT Technology Review. https://www.technologyreview.com/2023/10/23/1082189/data-poisoning-artists-fight-generative-ai/
- MIT Technology Review (2024). "The AI Lab Waging a Guerrilla War Over Exploitative AI." https://www.technologyreview.com/2024/11/13/1106837/ai-data-posioning-nightshade-glaze-art-university-of-chicago-exploitation/
- Anubis GitHub Repository. TecharoHQ. https://github.com/TecharoHQ/anubis
- Help Net Security (2025). "Anubis: Open-Source Web AI Firewall to Protect from Bots." https://www.helpnetsecurity.com/2025/12/22/anubis-open-source-web-ai-firewall-protect-from-bots/
- The Register (2025). "Anubis: Fighting the LLM Hordes with Proof of Work." https://www.theregister.com/2025/07/09/anubis_fighting_the_llm_hordes/
- Futurism (2026). "Engineers Deploy 'Poison Fountain' That Scrambles Brains of AI Systems." https://futurism.com/artificial-intelligence/poison-fountain-ai
- Anthropic (2025). "Poisoning Attacks on LLMs Require a Near-Constant Number of Poison Samples." https://www.anthropic.com/research/small-samples-poison
- arXiv (2024). "Poisoning Attacks on LLMs Require a Near-Constant Number of Poison Samples." arXiv:2510.07192. https://arxiv.org/abs/2510.07192
- Nature Medicine (2024). "Medical LLMs Vulnerable to Data Poisoning." https://www.nature.com/articles/s41591-024-03445-1
- AAAI (2024). "Scaling Trends for Data Poisoning in LLMs." https://ojs.aaai.org/index.php/AAAI/article/view/34929/37084
- Hubinger, E., Denison, C., Mu, J., et al. (2024). "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training." arXiv:2401.05566. https://arxiv.org/abs/2401.05566
- IETF AIPREF Working Group. "AI Preferences (aipref)." https://datatracker.ietf.org/wg/aipref/about/
- IETF Blog (2025). "Setting Standards for AI Preferences." https://www.ietf.org/blog/aipref-wg/
- European Commission (2024). "Regulatory Framework for AI." https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
- Securiti (2025). "EU Publishes Template for Public Summaries of AI Training Content." https://securiti.ai/eu-publishes-template-for-public-summaries-of-ai-training-content/
- US Copyright Office (2025). "Copyright and Artificial Intelligence: Part 3 - Generative AI Training." https://www.copyright.gov/ai/Copyright-and-Artificial-Intelligence-Part-3-Generative-AI-Training-Report-Pre-Publication-Version.pdf
- Harvard Law Review (2024). "NYT v. OpenAI: The Times's About-Face." https://harvardlawreview.org/blog/2024/04/nyt-v-openai-the-timess-about-face/
- UK Judiciary (2025). "Getty Images v. Stability AI Judgment." https://www.judiciary.uk/wp-content/uploads/2025/11/Getty-Images-v-Stability-AI.pdf
- DG Law (2025). "Court Rules AI Training on Copyrighted Works Is Not Fair Use." https://www.dglaw.com/court-rules-ai-training-on-copyrighted-works-is-not-fair-use-what-it-means-for-generative-ai/
- CNBC (2025). "Reddit User Data Battle: AI Industry Sues Perplexity Over Scraping Posts." https://www.cnbc.com/2025/10/23/reddit-user-data-battle-ai-industry-sues-perplexity-scraping-posts-openai-chatgpt-google-gemini-lawsuit.html
- RFC 9309 (2022). "Robots Exclusion Protocol." IETF. https://datatracker.ietf.org/doc/html/rfc9309
- NIST (2024). "AI Risk and Threat Taxonomy." https://csrc.nist.gov/csrc/media/Presentations/2024/ai-risk-and-threat-taxonomy/Vassilev-Day1-AI_Risk_and_Threat_Taxonomy.pdf
- The Register (2026). "AI Insiders Seek to Poison the Data That Feeds Them." https://www.theregister.com/2026/01/11/industry_insiders_seek_to_poison
- Mozilla Foundation (2024). "How Common Crawl Data Infrastructure Shaped the Battle Royale over Generative AI." https://www.mozillafoundation.org/en/blog/Mozilla-Report-How-Common-Crawl-Data-Infrastructure-Shaped-the-Battle-Royale-over-Generative-AI/
About VENOM
VENOM analyzes enforcement mechanisms in AI training data governance. We distinguish between signaling and enforcement, measure effectiveness where evidence exists, and acknowledge uncertainty where it does not. We are analysts, not advocates.
Our framework centers on a simple principle: when voluntary compliance fails, content creators require enforceable alternatives. Whether those alternatives are poisoning, proof-of-work, litigation, or standards with enforcement teeth, our role is rigorous analysis of costs, effectiveness, and collateral damage.
For more information: [venom.ai]
State of Defensive Data Poisoning 2026 VENOM Flagship Report January 2026