Publisher Defenses Against AI Scraping: Cost Imposition vs Poisoning
The escalating conflict between publishers and AI companies has produced two distinct categories of defensive mechanisms: cost imposition and value degradation. Understanding the difference matters because they impose burdens on different actors, scale differently with resources, and carry different risks of collateral damage.
This analysis examines both defense categories, who pays the costs, their effectiveness in practice, and the power dynamics they create or reinforce.
Key Takeaways
- Cost imposition defenses (proof-of-work, rate limiting, CAPTCHAs) impose computational or operational expenses on scrapers without corrupting data
- Value degradation defenses (data poisoning, watermarking, noise injection) reduce the quality or utility of scraped content for training purposes
- Small publishers face asymmetric costs: large platforms can afford sophisticated defenses, while individual creators rely on tools like Nightshade
- Voluntary signals like robots.txt fail predictably: 13.26% of AI bot requests ignored robots.txt in Q2 2025, up from 3.3% in Q4 202427
- The choice of defense mechanism reflects power dynamics. Those with resources choose cost imposition; those without choose value degradation
Two Categories of Defense
When publishers and content creators seek to prevent unauthorized AI training on their content, they face a strategic choice between two different approaches.
Cost Imposition: Making Scraping Expensive
Cost imposition defenses increase the computational, operational, or financial burden of collecting data without degrading the data itself. The scraper still gets clean data, but must pay more to obtain it.
Examples include:
Proof-of-work systems: Anubis, developed by Xe Iaso and deployed by UNESCO, GNOME, and Duke University1617, requires browsers to solve SHA-256 hash challenges before serving content. At standard difficulty, Anubis adds approximately 1.35 seconds per request.21 This is trivial for human users but prohibitively expensive for scrapers attempting millions of page requests. At difficulty 10, the computational cost multiplies by 570x.21
Rate limiting: Throttling request rates forces scrapers to slow down or spread requests across more IP addresses and infrastructure. Ethical scraping guidelines recommend approximately 1 request per second to avoid detection. Aggressive scraping may attempt hundreds or thousands of requests per second.
CAPTCHA systems: Modern CAPTCHA implementations have evolved from image recognition to proof-of-work challenges and behavioral analysis.12 Systems like Cloudflare Turnstile and AWS WAF use invisible, token-based verification that requires minimal user interaction but imposes computational costs on automated scrapers.13 As of January 2025, Google implemented more sophisticated CAPTCHA challenges and IP-based rate limiting in response to increased scraping activity.14
The key characteristic of cost imposition is symmetry: the burden scales with volume. A human reading a few pages encounters minimal friction. A scraper collecting millions of pages faces linearly increasing costs in CPU cycles, bandwidth, time, and infrastructure.
Value Degradation: Making Scraped Data Less Useful
Value degradation defenses reduce the quality or utility of training data without preventing access. The scraper can still collect the data, but that data may degrade model performance if used for training.
Examples include:
Data poisoning: Nightshade, developed at the University of Chicago and awarded Distinguished Paper at IEEE Security and Privacy 20244, generates adversarially perturbed images that appear visually normal but cause text-to-image models to mislearn concepts. As few as 50 tuned poison samples can attack Stable Diffusion SDXL with high probability.4 The poisoning bleeds through to semantically related concepts, amplifying impact beyond the targeted prompts.3
Style masking: Glaze, from the same University of Chicago research team, subtly alters artwork pixels so AI models perceive a different artistic style while humans see the original. Glaze has been downloaded approximately 7.5 million times5 and was recognized as a TIME Best Invention of 2023, demonstrating widespread adoption among artists concerned about style mimicry.
Watermarking: Digital watermarking embeds imperceptible patterns in images or audio that survive compression and transformation. Watermarks can help trace unauthorized use but also allow detection and filtering by sophisticated scrapers. Watermarking is primarily a provenance tool rather than a prevention mechanism.
Noise injection: Adding imperceptible statistical noise to content can degrade model quality during training. However, noise injection without adversarial optimization is often ineffective against large-scale training, as the signal-to-noise ratio improves with dataset size.
The key characteristic of value degradation is asymmetry: the burden affects all downstream uses of the data, not just the initial collection. A research team with limited filtering capacity may be harmed as much as or more than a well-resourced commercial scraper.

Who Bears the Costs?
The choice between cost imposition and value degradation has major implications for who pays, how much, and whether costs can be targeted at bad actors versus imposed broadly.
Cost Imposition: Scraper Burden, Implementation Resources Required
Cost imposition mechanisms impose their primary burden on scrapers but require publishers to implement and maintain the defensive infrastructure.
Implementation costs for publishers:
- Proof-of-work systems require deploying and configuring reverse proxy infrastructure. Anubis deployment involves Nginx configuration, SSL termination, and difficulty tuning
- Rate limiting requires traffic monitoring, anomaly detection, and dynamic throttling rules
- CAPTCHA systems often involve third-party services with ongoing subscription costs
- All approaches require technical expertise to deploy and tune for acceptable false positive rates
For large publishers with engineering teams, these costs are manageable. The Financial Times, for instance, has invested in bot detection and traffic analysis to identify and block AI scrapers.6 Major media companies negotiating licensing deals with AI companies (Time, News Corp, Associated Press) have the legal and technical resources to enforce access controls.
For small publishers and individual creators, implementation costs present a barrier. A solo blogger or artist may lack the technical expertise to deploy Anubis or configure rate limiting effectively. This creates a resource asymmetry: those with the most to protect may have the least capacity to implement cost imposition defenses.
Operational costs for scrapers:
The cost imposed on scrapers scales with volume and sophistication. For proof-of-work systems, scrapers must:
- Execute cryptographic puzzles for every request, consuming CPU cycles and electricity
- Maintain full browser environments (e.g., Chrome in headless mode) rather than lightweight HTTP clients, consuming roughly 500MB of RAM per instance
- Slow down collection to avoid triggering rate limits or behavioral analysis
- Invest in detection evasion (IP rotation, user-agent randomization, residential proxies)
According to industry analysis, the cost of maintaining and rebuilding scraping infrastructure has increased sharply as publishers deploy more defenses.14 This creates an escalating arms race where both sides invest resources continuously.
Symmetric versus asymmetric impact:
Cost imposition defenses are relatively symmetric: they burden large-scale commercial scrapers more than academic researchers or hobbyists who access content at lower volumes. A graduate student collecting a few thousand samples for research faces minimal friction. A scraper harvesting millions of pages faces large costs.
However, this symmetry is imperfect. Proof-of-work and CAPTCHA systems require JavaScript and modern browser capabilities, which may exclude:
- Users with accessibility needs who disable JavaScript
- Users on bandwidth-constrained connections (proof-of-work increases page load times)
- Archival systems like the Internet Archive that use lightweight crawlers
- Search engine crawlers that index content for discovery (though major search engines typically have whitelisted user agents)
Publishers implementing cost imposition must carefully tune difficulty levels and exemption lists to avoid blocking legitimate access.
Value Degradation: Indiscriminate Harm, Low Implementation Cost
Value degradation mechanisms impose their primary burden downstream, on anyone who trains on the degraded data, regardless of intent or authorization status.
Implementation costs for publishers:
Value degradation tools like Nightshade and Glaze have remarkably low implementation costs for individual creators:
- Nightshade and Glaze are free, downloadable tools with graphical interfaces
- Processing images takes minutes per image on consumer hardware
- No infrastructure deployment or ongoing maintenance required
- No technical expertise needed beyond basic software installation
This low barrier to entry explains why Glaze has seen 7.5 million downloads5 and why data poisoning has gained traction among individual artists and creators.12 When a solo artist cannot afford legal counsel or technical infrastructure, a simple desktop application that poisons their artwork becomes an accessible form of self-defense.
Coordinated poisoning initiatives like Poison Fountain, announced in January 2026, aim to scale this approach. By organizing multiple content sources to deploy poisoning simultaneously, such initiatives attempt to achieve impact that individual poisoning cannot.
Downstream costs: Indiscriminate impact:
The critical ethical and practical problem with value degradation is that it affects all downstream users of the data, not just the intended target.
Consider a poisoned image published on the public web:
-
Large commercial AI lab: Scrapes the poisoned image along with millions of others. May have data quality filters, anomaly detection, and human review processes to identify and remove poisoned samples. Can afford to discard suspicious data. Has legal and compliance teams monitoring preference signals and lawsuits. The poisoned data may be detected and filtered. Its impact may also be diluted across a massive training corpus.
-
Open-source dataset curator: Scrapes the poisoned image and includes it in a community dataset (e.g., LAION, Hugging Face). Limited resources for quality filtering. Relies on community reporting and automated heuristics. Poisoned data may persist in the dataset and affect all models trained on it.
-
Academic researcher: Downloads the open-source dataset for a research project on image generation or classification. Has no awareness that poisoned samples exist in the dataset. No resources to implement adversarial filtering. Publishes research results that may be affected by degraded model performance, wasting research effort and producing unreliable findings.
-
Hobbyist or student: Uses the open-source dataset to learn about machine learning or build a personal project. Encounters degraded model behavior, assumes they made a mistake in implementation, and wastes time debugging.
This inverse resource relationship means that value degradation defenses disproportionately harm those with the least capacity to detect and filter poisoned data. The intended targets, well-resourced commercial scrapers, have the most capability to mitigate the impact.
Irreversibility:
Value degradation defenses are difficult to undo once deployed. A poisoned image published to the public web may be:
- Scraped into multiple datasets before the creator reconsiders
- Redistributed and mirrored across the internet
- Incorporated into models that have already been trained and deployed
If a scraper begins respecting preference signals in response to the threat of poisoning, there is no clear mechanism to remove already-poisoned data from circulation. This contrasts with cost imposition mechanisms such as proof-of-work and rate limiting, which can be dialed down or disabled dynamically if compliance improves.

Publisher Economics: Who Can Afford Which Defenses?
The stark reality is that defensive capacity correlates with resources. Large publishers can afford both cost imposition and value degradation, while small publishers and individual creators have limited options.
Large Publishers and Platforms
Major publishers like the Financial Times, New York Times, and News Corp have:
- Dedicated engineering teams to implement bot detection, rate limiting, and access controls
- Legal departments to negotiate licensing agreements with AI companies (OpenAI, Anthropic, Google) or pursue litigation (Getty Images v. Stability AI, News Corp partnerships with OpenAI)
- Business development capacity to create revenue streams from content licensing
- Monitoring infrastructure to track which AI companies are scraping and at what volume
These resources allow a layered defense strategy:
- Signaling: Implement robots.txt and IETF AIPREF preference signals to establish clear intent and create legal evidence
- Access control: Deploy proof-of-work or require authentication for high-value content
- Legal enforcement: Pursue licensing deals or litigation when preference signals are ignored
- Selective poisoning: Reserve data poisoning as a targeted response if needed, with legal counsel assessing liability
This layered approach provides maximum power: preference signals for compliant actors, technical barriers for non-compliant scrapers, and legal remedies for persistent violators.
Small Publishers and Independent Creators
Individual bloggers, artists, photographers, and small publishers face a vastly different economic reality:
- No engineering team to deploy Anubis or configure rate limiting
- No legal budget for licensing negotiations or litigation
- Limited visibility into who is scraping their content and for what purpose
- No business development capacity to monetize AI training use of their work
For these creators, the only accessible defense is often value degradation via tools like Nightshade and Glaze. These tools:
- Are free and require no infrastructure
- Work on individual files without coordinating with platforms
- Provide immediate protection without waiting for legal processes
- Require no technical expertise beyond basic software use
The appeal is obvious: when you cannot afford lawyers or engineers, a desktop application that “protects” your work by poisoning it becomes a rational choice.
However, this accessibility comes with the ethical and practical costs discussed above: indiscriminate downstream harm, irreversibility, and disproportionate impact on under-resourced researchers and open-source projects.
The Centralization Risk
This resource asymmetry creates a centralization dynamic. If only large publishers can afford effective cost imposition defenses, and if value degradation defenses create too much collateral damage to be viable at scale, then the result is:
- Content consolidates on large platforms that can enforce access controls
- Independent creators either accept unauthorized scraping or poison their data with uncertain consequences
- Open-source and academic research bear the costs of collateral damage from poisoning
- AI companies preferentially license from large publishers who can negotiate, deepening the power imbalance
Mediavine, representing independent publishers, emphasized this concern: “Licensing must work for independent publishers, not just the top 1%. Scraping without permission is exploitation.”8
The risk is that defensive measures intended to protect creators instead accelerate consolidation, as only large players can afford effective, targeted defenses.
Effectiveness: Measurements and Tradeoffs

How well do these defenses actually work? Effectiveness depends on the adversary’s resources, the scale of scraping, and the sophistication of detection and evasion techniques.
Cost Imposition Effectiveness
Proof-of-work (Anubis):
Deployment data shows that Anubis “stops 90% of abusive crawlers” by requiring modern JavaScript features (ES6 modules, Workers, WebCrypto) that most scrapers do not support.1620 The 570x cost multiplier at high difficulty settings makes large-scale scraping economically prohibitive for adversaries without substantial computational budgets.21
However, proof-of-work is not impenetrable:
- Adversaries with sufficient resources can rent cloud compute to solve challenges
- Residential proxy networks can distribute computational costs
- Scrapers can slow down to stay below rate limits, trading time for reduced cost
- Content that requires real-time access (news) is harder to protect with high-latency challenges
Anubis is best suited for protecting content where timely access by scrapers is less critical (e.g., documentation, static blogs, archival content) and where blocking JavaScript-less crawlers is acceptable.1819
Rate limiting:
Traditional rate limiting has become less effective as scrapers adopt evasion techniques:
- IP rotation via cloud providers or residential proxies
- Distributed scraping across many ASNs (Autonomous System Numbers)
- User-agent spoofing to impersonate legitimate browsers
- Timing randomization to mimic human browsing patterns
Cloudflare data indicates that Anthropic’s ClaudeBot has crawl-to-refer ratios ranging from 38,000:1 to over 70,000:1, meaning it crawls vastly more content than it refers back to publishers.10 Despite rate limiting efforts, AI scrapers consumed significant resources from sites like Wikipedia’s Wikimedia Commons, prompting capacity restrictions.
Effective rate limiting requires behavioral analysis, machine learning-based anomaly detection, and continuous updating of detection rules. Only large publishers can afford this infrastructure.
CAPTCHA:
CAPTCHA effectiveness is declining as AI capabilities improve.12 Modern image recognition models can solve traditional CAPTCHAs with high accuracy. The industry has shifted to proof-of-work and behavioral analysis (Cloudflare Turnstile, hCaptcha), but these too face an arms race:
- CAPTCHA solving services offer human labor for $1-3 per 1,000 CAPTCHAs, making them economically viable for scrapers11
- Behavioral analysis can be defeated by using real browser automation (Selenium, Puppeteer) with realistic timing and mouse movement patterns
CAPTCHA remains effective mainly against low-sophistication scrapers. Well-resourced AI companies can bypass CAPTCHAs through automation or solving services.
Value Degradation Effectiveness
Data poisoning (Nightshade):
The Nightshade paper demonstrates high attack success rates with minimal poison samples (50 samples for Stable Diffusion SDXL).4 The prompt-specific targeting and semantic bleed-through make the attack effective even against large training datasets.34
However, effectiveness depends on:
- Poison fraction in the training corpus: At web scale (billions of images), achieving a meaningful poison fraction requires either coordinated efforts (Poison Fountain) or targeting specific high-value concepts
- Adversarial filtering: Sophisticated training pipelines can detect anomalous samples through outlier detection, ensemble-based filtering, or validation against clean reference datasets
- Adversarial training: Models can be trained to be robust against adversarial perturbations, reducing poisoning effectiveness
Research shows that detection techniques exist but do not scale to web-sized datasets without large computational cost. This creates an asymmetry: large AI companies can afford detection infrastructure, smaller players cannot.
The most significant effectiveness question is strategic: does poisoning deter unauthorized scraping, or does it trigger an arms race in adversarial robustness that large AI companies win?
Proponents argue that even imperfect poisoning increases the cost and risk of scraping without consent, making licensing economically preferable. Critics warn that widespread poisoning will push investment in detection and robustness, restoring the advantage to large, well-resourced actors.
Watermarking:
Watermarking effectiveness is limited because:
- Watermarks can be detected and removed by adversaries aware of their presence
- Watermarking does not prevent scraping; it only enables provenance tracking after the fact
- Adversaries can apply transformations (compression, cropping, noise addition) to degrade watermarks
Watermarking is best used as a complement to other defenses: it provides evidence for legal claims but does not prevent unauthorized use.
Noise injection:
Simple noise injection is largely ineffective against large-scale training. As dataset size increases, the signal-to-noise ratio improves, and random noise averages out. Adversarial noise (optimized perturbations like Nightshade) is required for meaningful impact, which brings us back to data poisoning with all its tradeoffs.
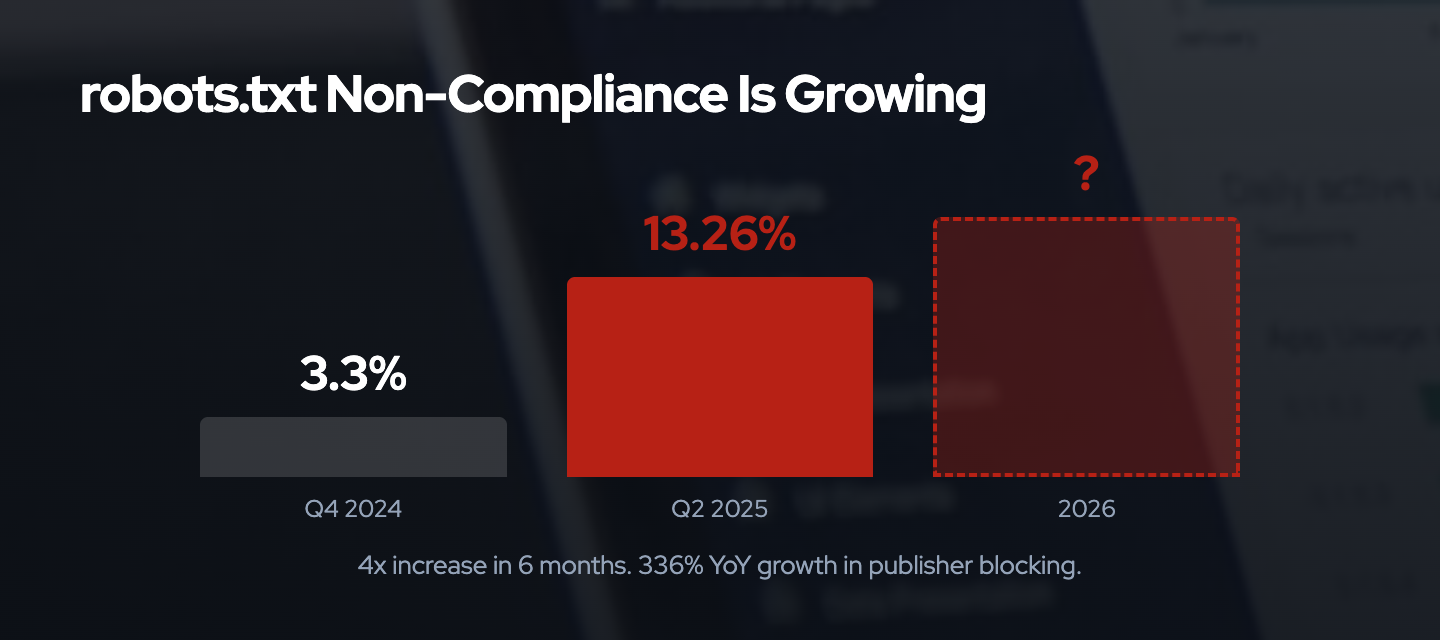
Why Voluntary Signals Fail Predictably
The escalation from signaling to enforcement reflects a predictable failure mode: voluntary compliance mechanisms work only when incentives align or enforcement mechanisms exist. Neither condition holds for AI training data collection.
robots.txt Compliance Data
robots.txt, developed in 1994 and standardized as RFC 9309 in September 202228, depends entirely on voluntary compliance. The RFC explicitly states that robots.txt is “not a substitute for valid content security measures.”28
Recent compliance data shows accelerating non-compliance:
- Q4 2024: 3.3% of AI bot requests ignored robots.txt directives27
- Q2 2025: 13.26% of AI bot requests ignored robots.txt directives (a 4x increase in two quarters)27
- A Duke University study (2025) found that several categories of AI-related crawlers never request robots.txt at all27
Specific AI companies show varying compliance levels:
- Approximately 5.6 million websites blocked OpenAI’s GPTBot via robots.txt by mid-2025, up from 3.3 million in early July 2025 (a 70% increase in weeks)26
- Anthropic’s ClaudeBot is blocked on approximately 5.8 million websites, up from 3.2 million in early July 202526
- Despite widespread blocking, AI scraping activity increased by 40% between Q3 and Q4 202422
Evasion Techniques
AI companies and their contractors employ well-documented evasion techniques:
- User-agent spoofing: Impersonating mainstream browsers (Chrome, Firefox) to bypass user-agent-based blocking
- IP and ASN rotation: Rapidly changing IP addresses and autonomous systems to avoid IP-based rate limits
- Third-party proxies: Using browser-as-a-service proxies and residential proxy networks to obscure origin
- Crawler rebranding: Companies like Anthropic and Perplexity have “circumvented robots.txt by renaming or spinning up new scrapers to replace the ones that appeared on popular blocklists”25
These techniques are not zero-cost, but for companies raising hundreds of millions in venture capital funding, the cost of evasion is trivial compared to the value of training data.
Incentive Misalignment
Voluntary compliance fails because incentives are misaligned:
AI companies benefit from non-compliance:
- Training data is the primary input to foundation models; more data generally improves performance
- Licensing deals are expensive; scraping without permission is free (until litigation succeeds)
- First-mover advantages in AI capabilities incentivize rapid data collection before regulations or norms solidify
- Enforcement is uncertain: litigation is slow, outcomes are unpredictable, and statutory damages may be lower than the value of improved models
Publishers have limited enforcement options:
- Litigation is expensive and slow (Getty Images v. Stability AI, Authors Guild v. OpenAI are ongoing years after filing)15
- Technical enforcement (paywalls, authentication) may reduce traffic and ad revenue
- Reputation-based pressure is ineffective when venture capital funding exceeds near-term revenue concerns
- Collective action is difficult to organize across thousands of independent publishers
In this environment, voluntary compliance depends on either reputational incentives (which are weak) or the credible threat of enforcement (which is currently lacking). The result is predictable: widespread non-compliance.
IETF AIPREF: Will Standardized Signals Help?
The IETF AI Preferences (AIPREF) Working Group, chartered in January 20252930, is developing standardized mechanisms for expressing preferences about AI content collection and processing. Key drafts include vocabulary specifications (draft-ietf-aipref-vocab-05) and attachment mechanisms (draft-ietf-aipref-attach-04).
AIPREF aims to provide clearer, more granular signaling than robots.txt, with explicit semantics for AI-specific use cases (training, fine-tuning, inference).24
However, AIPREF does not solve the voluntary compliance problem. It provides clearer evidence of intent, which may:
- Strengthen legal claims for unauthorized use
- Create reputational incentives for compliance (by making violations more clearly intentional)
- Allow automated compliance checking and auditing
But like robots.txt23, AIPREF has no technical enforcement mechanism. It signals preferences; it does not prevent access. Without legal backing (e.g., statutory liability for ignoring AIPREF signals) or technical enforcement (cost imposition, value degradation), AIPREF risks becoming another ignored standard.
The path forward likely requires both: standardized preference signals (AIPREF) to establish clear norms and legal evidence, and technical enforcement mechanisms (cost imposition, selective value degradation) to impose costs on non-compliance.
Power Dynamics: Does This Rebalance or Centralize?
The critical strategic question is whether the proliferation of defensive mechanisms rebalances power between publishers and AI companies, or whether it accelerates centralization and entrenches existing power structures.
Rebalancing Potential
Optimistic accounts argue that defensive mechanisms, particularly low-cost tools like Nightshade, democratize enforcement:
- Individual creators can protect their work without legal budgets or engineering teams
- Coordinated initiatives like Poison Fountain create collective bargaining power
- Proof-of-work tools like Anubis are open-source and deployable by anyone with basic technical skills
- Standardized signals like AIPREF provide transparency and evidence for legal claims
If these tools impose sufficient costs on unauthorized scraping, AI companies may find it economically preferable to negotiate licenses with content creators, creating a more balanced marketplace.
The University of Chicago Nightshade team explicitly positions their work as increasing bargaining power: “The researchers position Nightshade as a defensive tool to increase the cost of training on unlicensed data, making it economically preferable for AI companies to negotiate licenses with content creators.”5
Centralization Risks
Pessimistic accounts warn that defensive measures may accelerate centralization:
Resource asymmetries favor large actors:
- Large publishers can afford layered defenses (signaling + cost imposition + legal enforcement)
- Small publishers can afford only value degradation (with collateral damage concerns)
- Large AI companies can afford adversarial robustness and detection infrastructure
- Small AI projects and academic researchers cannot, suffering disproportionate harm from poisoning
Licensing deals favor established players:
- Large media companies (Time, News Corp, Associated Press) have negotiated individual licensing deals with OpenAI and other AI companies
- Small publishers lack negotiating power and are often excluded from licensing discussions
- The economics of licensing do not work for most publishers: “No amount of licensing revenue can offset traffic losses because the licensing revenue doesn’t take into consideration the true LTV (lifetime value) of a reader”7
Technical arms race advantages:
- If poisoning triggers an arms race in adversarial robustness and detection, large AI companies with ML research teams will likely prevail
- Open-source projects like LAION and Hugging Face lack resources to compete in this arms race
- The result may be that only large, well-resourced AI companies can train high-quality models, while open-source and academic efforts are hampered by poisoned data
Legal uncertainty discourages independent action:
- Accountability for poisoned data that causes downstream harm remains unclear
- Individual creators may face legal risk if poisoning causes safety issues in deployed models
- Large publishers with legal teams can assess and manage this risk; small creators cannot
The Collective Action Problem
Over 80 media executives met in New York under the IAB Tech Lab banner in late 2024 to address unauthorized AI content scraping.9 Google and Meta participated, but the AI companies most implicated (OpenAI, Anthropic, and Perplexity) declined to attend.9
This highlights the collective action problem: publishers compete with each other for traffic and revenue, making coordination difficult. AI companies face no such coordination problem; they can unilaterally scrape while publishers must organize collectively to resist.
Poison Fountain represents an attempt to solve this collective action problem through coordinated value degradation. Whether such initiatives can scale sufficiently to impose meaningful costs on well-resourced adversaries remains an open question.
Synthesis: Defense as a Function of Resources
The choice between cost imposition and value degradation ultimately reflects resource constraints and risk tolerance:
If you have resources (large publishers, platforms):
- Implement layered defense: signaling (robots.txt, AIPREF) + cost imposition (proof-of-work, rate limiting) + legal enforcement (licensing negotiations, litigation)
- Invest in bot detection, traffic analysis, and anomaly detection
- Pursue licensing revenue where viable
- Reserve value degradation (poisoning) as a targeted, last-resort measure with legal counsel
If you lack resources (individual creators, small publishers):
- Implement signaling (robots.txt, AIPREF) to establish intent and create legal evidence
- Use accessible value degradation tools (Nightshade, Glaze) with awareness of collateral damage risks
- Participate in collective action initiatives (Poison Fountain, industry coalitions)
- Advocate for legal frameworks that make enforcement accessible without requiring individual technical or legal resources
If you are an AI company:
- Recognize that voluntary compliance failures are driving escalation
- Invest in adversarial robustness and data provenance to mitigate poisoning risks
- Negotiate licensing deals where economically viable (large publishers) rather than relying on scraped data
- Participate in standards development (AIPREF) to create clearer norms and compliance mechanisms
- Understand that continued non-compliance will likely trigger regulatory intervention
If you are a researcher or open-source developer:
- Advocate for legal and technical frameworks that distinguish between commercial exploitation and research/educational use
- Support development of clean, curated datasets with clear provenance
- Participate in standards efforts to create exemptions or safe harbors for research use
- Implement data validation and anomaly detection in training pipelines, even with limited resources
- Document the collateral damage from indiscriminate value degradation defenses to inform policy discussions
Conclusion
The distinction between cost imposition and value degradation is not merely technical. It reflects deeper questions about power, resources, and who bears the costs of enforcement in the absence of effective legal frameworks.
Cost imposition defenses like proof-of-work and rate limiting impose symmetric burdens that scale with scraping volume. They require resources to implement but avoid corrupting data and can be targeted at bad actors. They favor large publishers who can afford the infrastructure.
Value degradation defenses like data poisoning impose asymmetric burdens that affect all downstream users indiscriminately. They have low barriers to entry, making them accessible to individual creators, but create collateral damage that disproportionately harms under-resourced researchers and open-source projects. They risk accelerating centralization if large AI companies can afford detection and robustness infrastructure while smaller actors cannot.
The escalation from voluntary signaling (robots.txt) to technical enforcement reflects a predictable failure mode: when incentives misalign and legal frameworks lag, unilateral technical measures become rational, even if they create negative externalities.
The path forward requires multiple interventions:
- Legal frameworks: Statutory protections for preference signals, transparency requirements for training data sources, liability frameworks for non-compliance
- Technical standards: AIPREF and related efforts to create clearer, more enforceable norms
- Economic models: Licensing frameworks that work for small publishers, not just the top 1%
- Collective action: Industry coalitions to coordinate defense and advocacy
- Research: Better detection, filtering, and robustness techniques that reduce collateral damage from value degradation defenses
The current state favors large actors on both sides: large publishers can afford effective defenses, and large AI companies can afford evasion and robustness. The question is whether emerging standards, collective action, and legal frameworks can rebalance this power structure or whether the arms race will further entrench centralization.
Understanding who can afford which defenses, and who bears the costs of each approach, is essential for anyone navigating this space. This applies whether you are a publisher, AI developer, researcher, or policy maker.
References
- Lakera - Introduction to Data Poisoning: A 2025 Perspective:. https://www.lakera.ai/blog/training-data-poisoning
- IBM - What Is Data Poisoning?:. https://www.ibm.com/think/topics/data-poisoning
- MIT Technology Review - This new data poisoning tool lets artists fight back against generative AI:. https://www.technologyreview.com/2023/10/23/1082189/data-poisoning-artists-fight-generative-ai/
- Nightshade Academic Paper (arXiv):. https://arxiv.org/html/2310.13828v3
- Nightshade Project Page:. https://nightshade.cs.uchicago.edu/whatis.html
- Digiday - The net is tightening on AI scraping (Financial Times interview):. https://digiday.com/media/the-net-is-tightening-on-ai-scraping-annotated-qa-with-financial-times-head-of-global-public-policy-and-platform-strategy/
- A Media Operator - The Economics of an AI Future Doesn't Work for Publishers:. https://www.amediaoperator.com/analysis/the-economics-of-an-ai-future-doesnt-work-for-publishers/
- MonetizeMore - Dealing With Revenue Loss Due to AI Content Scraping:. https://www.monetizemore.com/blog/revenue-loss-due-to-ai-content-scraping/
- Digiday - Here are the biggest misconceptions about AI content scraping:. https://digiday.com/media/here-are-the-biggest-misconceptions-about-ai-content-scraping/
- Cloudflare - AI Labyrinth Traps Scrapers:. https://www.deeplearning.ai/the-batch/cloudflares-ai-labyrinth-traps-scrapers-with-decoy-pages/
- Prosopo - Real-Time Bot, Scraping, and Cyber Threat Defense:. https://prosopo.io/
- Medium - The Silent Gatekeeper: Why CAPTCHA is Dying and What Comes Next in 2026:. https://medium.com/@tuguidragos/the-silent-gatekeeper-why-captcha-is-dying-and-what-comes-next-in-2025-f387fa334bbd
- ALTCHA - Next-Gen Captcha and Spam Protection:. https://altcha.org/
- ScrapingBee - Top Web Scraping Challenges in 2025:. https://www.scrapingbee.com/blog/web-scraping-challenges/
- Above the Law - Google Built Its Empire Scraping The Web. Now It's Suing To Stop Others From Scraping Google:. https://abovethelaw.com/2025/12/google-built-its-empire-scraping-the-web-now-its-suing-to-stop-others-from-scraping-google/
- Help Net Security - Anubis: Open-source web AI firewall:. https://www.helpnetsecurity.com/2025/12/22/anubis-open-source-web-ai-firewall-protect-from-bots/
- LWN - Anubis sends AI scraperbots to a well-deserved fate:. https://lwn.net/Articles/1028558/
- Ben Tasker - Deploying Anubis to protect against AI scrapers:. https://www.bentasker.co.uk/posts/blog/the-internet/deploying-anubis-to-block-ai-bots.html
- GitHub - Anubis Repository:. https://github.com/TecharoHQ/anubis
- The Register - Anubis: Fighting off the hordes of LLM bot crawlers:. https://www.theregister.com/2025/07/09/anubis_fighting_the_llm_hordes/
- Mike Bommarito - Anubis benchmark: measuring proof-of-work overhead:. https://michaelbommarito.com/wiki/ai-society/anubis-benchmark-analysis/
- The Register - Publishers say no to AI scrapers:. https://www.theregister.com/2025/12/08/publishers_say_no_ai_scrapers/
- Plagiarism Today - Does Robots.txt Matter Anymore?:. https://www.plagiarismtoday.com/2025/10/21/does-robots-txt-matter-anymore/
- DEV Community - New AI web standards and scraping trends in 2026:. https://dev.to/astro-official/new-ai-web-standards-and-scraping-trends-in-2026-rethinking-robotstxt-3730
- Auto-Post.io - AI Agents Ignore robots.txt: Risks for Publishers:. https://auto-post.io/blog/ai-agents-ignore-robots-txt
- GitHub - ai-robots-txt: A list of AI agents and robots to block:. https://github.com/ai-robots-txt/ai.robots.txt
- arXiv - Scrapers selectively respect robots.txt directives:. https://arxiv.org/html/2505.21733v1
- RFC 9309 - Robots Exclusion Protocol:. https://datatracker.ietf.org/doc/html/rfc9309
- IETF AIPREF Working Group:. https://datatracker.ietf.org/wg/aipref/about/
- IETF Blog - AIPREF Working Group:. https://www.ietf.org/blog/aipref-wg/