The AI Crawler Compliance Crisis: Who Plays by the Rules?
Key Takeaways
- AI crawler robots.txt non-compliance rose from 3.3% in Q4 2024 to 30% in Q4 2025, a nearly tenfold increase in one year1
- OpenAI’s ChatGPT-User is the worst offender at 42% non-compliance; Meta accounts for 52% of total AI crawler volume12
- Cloudflare processes 50 billion AI crawler requests per day. Anthropic’s crawl-to-refer ratio peaked at 500,000 pages crawled per referral sent back3
- Publishers are responding: 5.8 million sites now block ClaudeBot, top-500 publisher traffic declined 27% year-over-year, and the largest AI copyright settlement reached $1.5 billion45
- The compliance trajectory is accelerating downward. Better signaling (AIPREF) helps establish intent, but the economic incentives driving non-compliance remain unchanged
The Numbers
The web operated on a social contract for thirty years: crawlers respect robots.txt, publishers allow indexing, and users find content through search. AI training broke this contract. The data tells the story.
TollBit, which monitors crawler behavior across publisher networks, tracked robots.txt non-compliance rates for AI bots across three quarters1:
- Q4 2024: 3.3% non-compliance
- Q2 2025: 13.26% non-compliance
- Q4 2025: 30% non-compliance
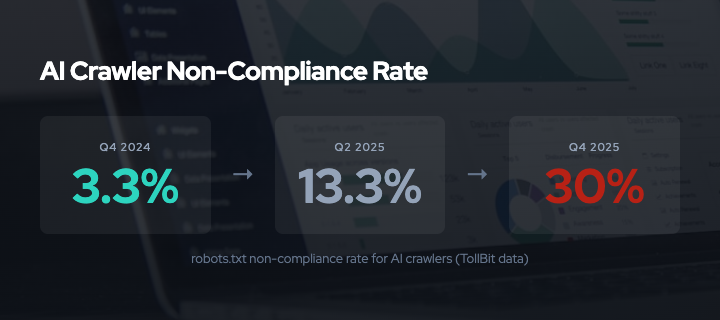
That is a tenfold increase in one year. And it understates the problem, because it only counts crawlers that identify themselves honestly. DataDome found that 5.7% of AI crawler user-agent strings are spoofed6 — bots that claim to be browsers or search engine crawlers to bypass robots.txt entirely.
A Duke University study offers a more granular picture7. Researchers monitored 130 bots over 40 days, recording 3.9 million requests. They found compliance drops sharply with stricter directives: 60.9% of bots complied with crawl-delay directives, but only 30.7% complied with complete disallow rules. Bytespider (ByteDance’s crawler) had 0% endpoint access compliance — it ignored every restriction.
Less than 40% of AI bots re-checked robots.txt within a week. Many appear to fetch the file once, cache it, and never update. Some never fetch it at all.
Who Crawls What
Not all AI companies crawl equally. Fastly’s network data provides a breakdown of AI crawler volume2:
- Meta: 52% of AI crawler traffic
- Google: 23%
- OpenAI: 20%
- Others: 5%
Meta’s dominance is striking. Their crawler infrastructure generates more than half of all AI bot traffic observed by Fastly, with fetcher bots reaching 39,000 requests per minute. This volume exceeds what most publishers provision for.
Cloudflare’s data adds another dimension: the crawl-to-refer ratio3. This measures how many pages a company crawls versus how many visits it sends back to publishers. Search engines historically maintained roughly balanced ratios — they crawl your site, they send you traffic. AI companies do not.
- Anthropic: 38,000 to 70,900 pages crawled per referral sent. Peak ratio observed: 500,000:1
- OpenAI: 887:1
- Google (Search): roughly 1:1
Anthropic crawls up to half a million pages for every single user it directs to a publisher’s site. There is no reciprocal relationship.
The Infrastructure Bill
AI crawlers do not just take data. They consume infrastructure. The costs are real, measurable, and borne entirely by publishers.

IETF Datatracker: ChatGPT-related requests increased 4,000% in one year, forcing the IETF to migrate to CDN infrastructure8. The organization that literally writes internet standards was overwhelmed by AI crawlers scraping those standards.
Wikimedia: Bandwidth increased 50% since January 2024. Bots consume 65% of expensive server-side rendering resources despite accounting for 35% of pageviews9.
Read the Docs: Blocking AI crawlers reduced traffic by 75% and saved $1,500 per month in hosting costs. A single crawler consumed 73 terabytes in one month10.
GNOME GitLab: 96.8% of traffic was automated. After deploying Anubis proof-of-work challenges, the project halved its pod scaling requirements11.
Forgejo: Experienced attack waves of 600,000 unique IPs per day from crawlers using residential proxy networks at approximately $0.10 per gigabyte12.
SourceHut: Drew DeVault, the founder, reported spending 20% to 100% of his engineering time on crawler mitigation instead of building his product12.
These are not edge cases. They represent the experience of open-source infrastructure, non-profits, and independent publishers — the organizations least equipped to absorb the costs.
The Economic Asymmetry
The fundamental problem is an economic imbalance. AI companies extract value from publisher content without compensating for the infrastructure costs of that extraction or the lost revenue from reduced traffic.
Top-500 publisher traffic declined 27% year-over-year5. This translates to approximately $2 billion in annual advertising revenue losses. AI referral traffic accounts for just 0.1% of total publisher referrals. Click-through rates from AI tools dropped from 0.8% to 0.27% across 20255.
The World Economic Forum stated it plainly in January 2026: “AI has broken the web’s core economic bargain.”13
Search engines maintained the bargain because they needed ongoing access to fresh content. The incentive was symmetric: crawl the site, index the content, send users to it, repeat. AI training is asymmetric: scrape once, build models, generate competing content, never return. There is no recurring relationship that creates accountability.
This asymmetry explains the compliance trajectory. When an AI company can extract substantial model value from a single crawl of the web, a few weeks of ignoring robots.txt is a small cost. The potential legal liability is large (see below), but litigation risk is diffuse, and most publishers cannot sue.
Publisher Responses
Publishers are not passive. The response has been swift and broad.
Blocking at scale: 5.6 million websites added GPTBot to their robots.txt disallow lists. 5.8 million block ClaudeBot. 79% of top news sites now block AI training bots4.
Platform-level defenses: Cloudflare, which proxies approximately 20% of the web, deployed multiple AI-specific features in 20253:
- AI Labyrinth (March 2025): Serves AI crawlers procedurally generated content to waste their resources
- AI Crawl Control (July 2025): Default-block for AI crawlers on new sites
- Pay Per Crawl (July 2025): HTTP 402-based marketplace allowing publishers to set a price for AI access (private beta)
- Managed Robots.txt (October 2025): Centrally maintained blocklists for known AI crawlers
Proof-of-work challenges: Anubis, the open-source PoW system, has been downloaded over 200,000 times and deployed by Duke University, UNESCO, kernel.org, FreeBSD, GNOME, FFmpeg, and WINE11. Duke reported blocking 90% of unwanted traffic (4 million requests per day filtered).
Legal action: The litigation landscape escalated dramatically in 2025-2026:
- Bartz v. Anthropic (September 2025): Settled for $1.5 billion, the largest copyright settlement in U.S. history14
- UMG v. Anthropic (January 2026): Filed for $3.1 billion, alleging Anthropic’s co-founder used BitTorrent to pirate training data14
- NYT v. Perplexity (December 2025): Alleging robots.txt circumvention with over 175,000 blocked access attempts documented15
- Google v. SerpApi (December 2025): Invoking DMCA anti-circumvention provisions for search result scraping
The Collateral Damage Problem
The publisher response is effective but indiscriminate. When sites block AI crawlers wholesale, they also block legitimate uses.
The most consequential example: publishers blocking the Internet Archive16. In January-February 2026, aggressive robots.txt updates intended to block AI crawlers caught the Wayback Machine as collateral damage. News page captures dropped 87%. The web’s historical record is being eroded by publisher self-defense against AI scraping.

This is the vocabulary problem that AIPREF is designed to solve. Robots.txt forces a binary choice: allow everything or block everything. A publisher cannot say “the Internet Archive may crawl for preservation, but Anthropic may not crawl for training.” With AIPREF’s Content-Usage vocabulary, this distinction becomes expressible: search=y, train-ai=n permits archiving and search indexing while blocking AI training use17.
But AIPREF is still in draft. The current vocabulary (v05, December 2025) defines only two categories (train-ai and search), and the working group is still debating scope. IETF 125 in Shenzhen (March 2026) and a three-day Toronto interim (April 2026) are the next decision points. Even under optimistic timelines, a published RFC is at least a year away.
What Compliance Would Require
The compliance crisis is not primarily a technical problem. The technology exists. Robots.txt is simple to parse. HTTP headers are simple to read. The problem is incentive alignment.
For compliance to improve, one of three things must change:
1. Legal costs must exceed extraction value. The Bartz settlement ($1.5 billion) and UMG lawsuit ($3.1 billion) are beginning to establish this. But litigation is slow, expensive, and available only to well-resourced publishers. The open-source projects and non-profits bearing the heaviest infrastructure costs are the least able to sue.
2. Technical enforcement must make non-compliance expensive. Proof-of-work (Anubis), tarpits (Nepenthes, AI Labyrinth), rate limiting, and data poisoning all impose costs on non-compliant crawlers. But determined actors with large budgets can overcome these defenses. Codeberg documented bots bypassing Anubis within months of deployment11.
3. Market mechanisms must make compliance profitable. Cloudflare’s Pay Per Crawl experiment is the most interesting development here. If AI companies can pay publishers directly for crawl access, the incentive flips from extraction to transaction. The HTTP 402 Payment Required status code, largely unused since HTTP/1.1, may finally have a purpose.
None of these mechanisms work in isolation. Together, they create a layered system where clearer signals (AIPREF) establish intent, technical defenses impose costs on violation, legal frameworks provide recourse, and market mechanisms offer an alternative path.
For a deeper analysis of how cost imposition and value degradation defenses work together, see our Cost Imposition vs Value Degradation framework. For background on the signaling standard that could resolve the vocabulary problem, see our AIPREF explainer.
Last updated: March 2026
References
- TollBit (2025). AI Crawler Compliance Reports, Q4 2024 - Q4 2025. https://www.tollbit.com/blog/ai-crawler-report
- Fastly (2025). "AI Crawler Impact on Web Infrastructure." https://www.fastly.com/blog/how-to-manage-ai-assistant-and-crawler-traffic
- Cloudflare (2025). "AI Audit: Understanding How AI Bots Interact with Your Content." https://blog.cloudflare.com/ai-audit
- Stytch Blog (2025). "How to Block AI Web Crawlers." https://stytch.com/blog/how-to-block-ai-web-crawlers/
- Atlantic (2025). "The Traffic Crisis: How AI Is Reshaping Publisher Economics." https://www.theatlantic.com/technology/archive/2025/ai-publisher-traffic/
- DataDome (2025). "AI Bot Detection and User-Agent Spoofing Analysis." https://datadome.co/bot-management-protection/ai-web-scraper-bot/
- Duke University (2025). "Empirical Analysis of AI Crawler Compliance with robots.txt." https://arxiv.org/abs/2503.04546
- IETF Blog (2025). "AI Traffic Impact on IETF Infrastructure." https://www.ietf.org/blog/aipref-wg/
- Wikimedia Foundation (2025). "Bot Traffic and Server Resource Analysis." https://meta.wikimedia.org/wiki/Research:Bot_traffic_analysis
- Read the Docs Blog (2025). "Blocking AI Crawlers: Results and Impact." https://blog.readthedocs.com/ai-crawlers/
- Anubis GitHub Repository. TecharoHQ. https://github.com/TecharoHQ/anubis
- DeVault, D. "Please Stop Externalizing Your Costs Directly Into My Face." SourceHut Blog. https://drewdevault.com/
- World Economic Forum (2026). "AI and the Future of the Open Web." https://www.weforum.org/stories/2026/01/ai-open-web/
- Reuters (2025-2026). "AI Copyright Litigation Tracker." https://www.reuters.com/legal/litigation/
- New York Times (2025). "NYT Sues Perplexity AI for Systematic Content Scraping." https://www.nytimes.com/2025/12/perplexity-lawsuit.html
- Internet Archive (2026). "Impact of AI Crawler Blocking on Web Archiving." https://blog.archive.org/
- Keller, P., Thomson, M. "A Vocabulary For Expressing AI Usage Preferences." draft-ietf-aipref-vocab-05. https://datatracker.ietf.org/doc/html/draft-ietf-aipref-vocab-05